[1] 0.01063538Week 9
Sociology 106: Quantitative Sociological Methods
March 17, 2026
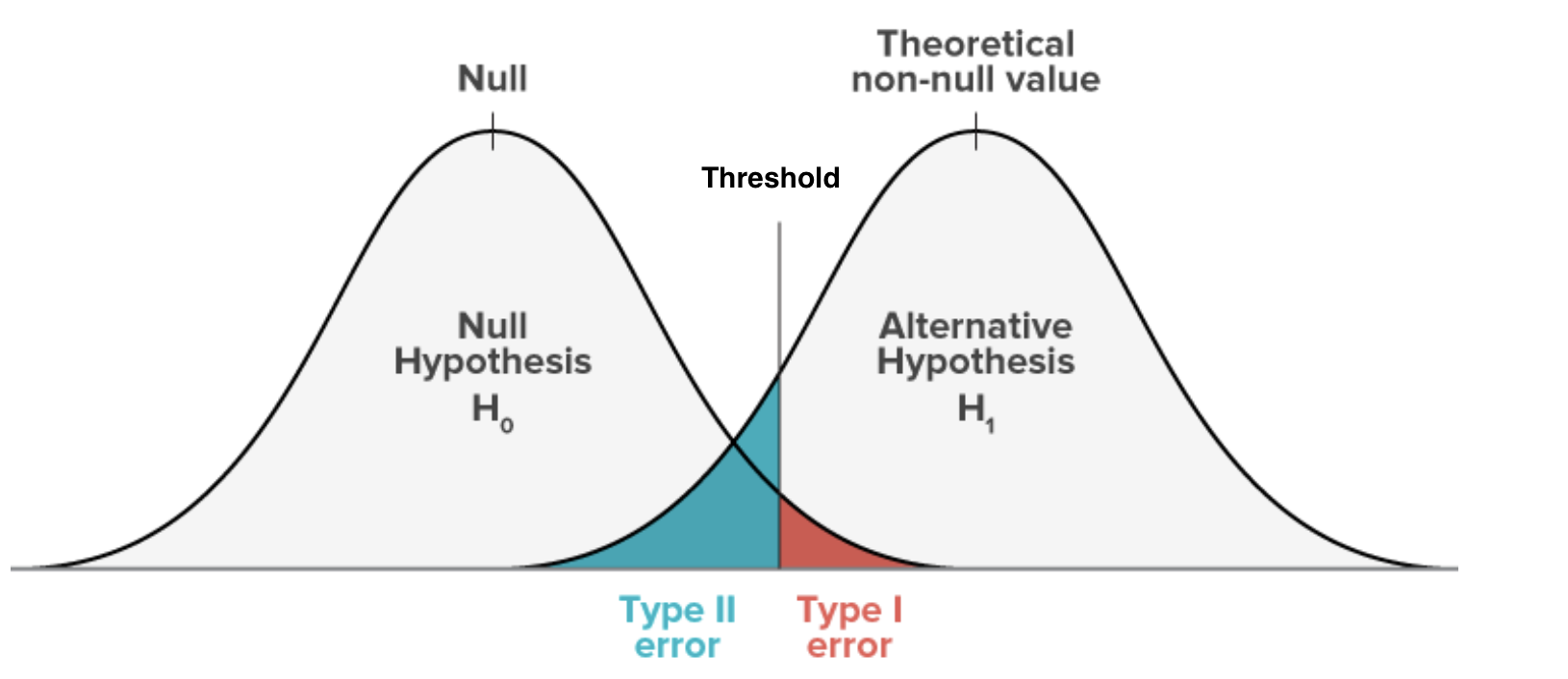
Trade-off between Type I and II Error
One- and Two-Tailed Tests
A one-tailed test checks for a significant effect in one specific direction
- \(H_0: \pi \leq 0.50\) vs. \(H_1: \pi > 0.50\)
- All of \(\alpha\) is in one tail — critical value is lower — and therefore easier to reject \(H_0\), but only if the effect is in the predicted direction
James Bond (one-tailed): Did he perform better than random guessing?
A two-tailed test checks for a significant effect in either direction
- \(H_0: \pi = 0.50\) vs. \(H_1: \pi \neq 0.50\)
- \(\alpha\) is split equally — 2.5% in each tail — critical value is higher ; more conservative and more common in social science
James Bond (two-tailed): Did he perform differently from random guessing?
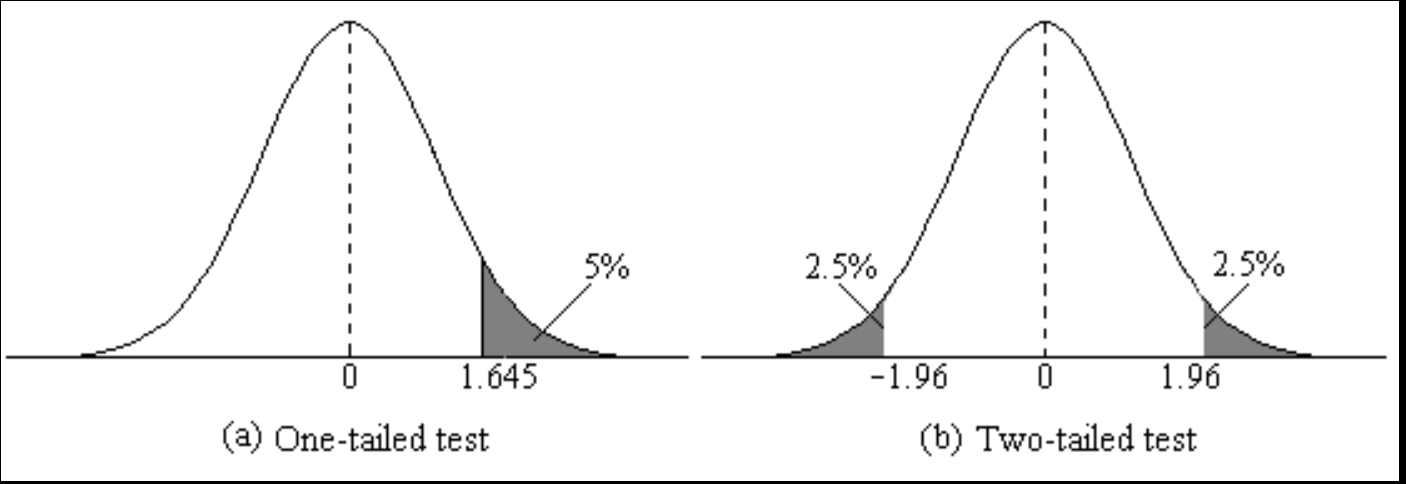
- One-tailed: rejection region entirely on one side
- Two-tailed: rejection region split — requires a more extreme result to reject
| Scenario | Recommended |
|---|---|
| Theory strongly predicts the direction | One-tailed (use sparingly!) |
| No strong directional prediction | Two-tailed (default) |
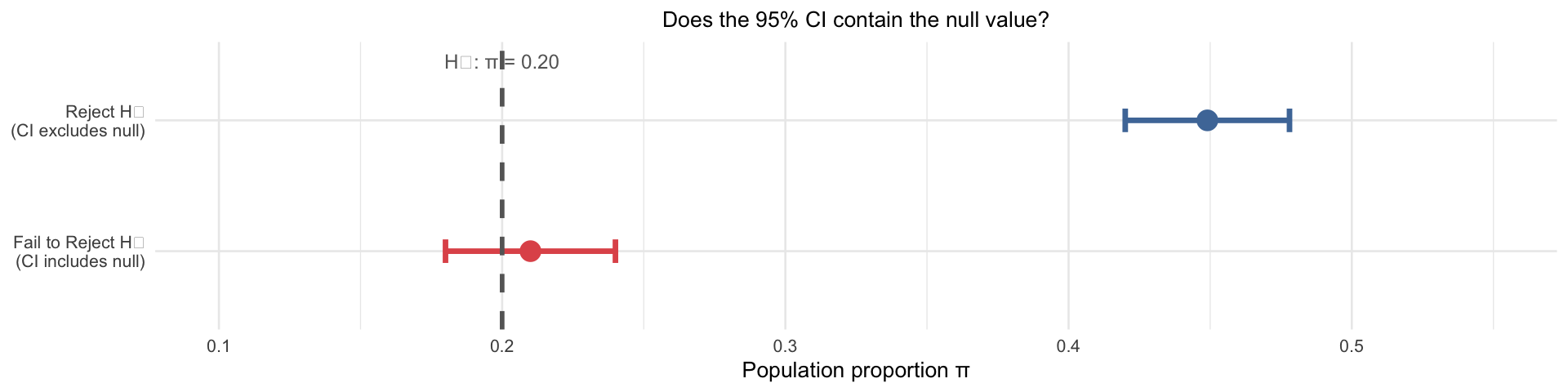
CIs and Hypothesis Tests
Last week’s confidence intervals and today’s hypothesis tests are two sides of the same coin:
- If the 95% CI does not contain the null value \(\mu_0\) → reject \(H_0\) at \(\alpha = 0.05\)
- If the 95% CI contains the null value → fail to reject \(H_0\)
Test 1: One-Sample t-Test for a Mean
Compare the sample to the population.
General form of the one-sample t-test:
\[H_0: \mu = \mu_0 \qquad \text{(sample mean equals a specified population value)}\]
\(H_1\) depends on whether the research hypothesis predicts a direction:
| Alternative | Test type | When to use |
|---|---|---|
| \(H_1: \mu \neq \mu_0\) | Two-tailed | No predicted direction — default choice |
| \(H_1: \mu > \mu_0\) | One-tailed (upper) | Theory predicts sample is higher than \(\mu_0\) |
| \(H_1: \mu < \mu_0\) | One-tailed (lower) | Theory predicts sample is lower than \(\mu_0\) |
Running example: Is the mean hours worked per week by U.S. adults equal to 40 hours?
- \(H_0: \mu = 40\) — the population mean is 40 hours
- \(H_1: \mu \neq 40\) — the population mean is something other than 40 (two-tailed)
- Significance level: \(\alpha = 0.05\)
Under \(H_0\), the test statistic follows a t-distribution with \(df = n - 1\):
\[t = \frac{\bar{x} - \mu_0}{s / \sqrt{n}}\]
| Step | What to compute | Formula/Rule |
|---|---|---|
| 1 | State \(H_0\) and \(H_1\) | \(H_0: \mu = \mu_0\); choose \(H_1\) based on theory |
| 2 | One- or two-tailed? | Does theory predict a direction? → one-tailed; otherwise → two-tailed (default) |
| 3 | Sample mean & SE | \(\bar{x}\); \(SE = s / \sqrt{n}\) |
| 4 | t-statistic | \(t = (\bar{x} - \mu_0) / SE\) |
| 5 | p-value | See below |
mu = 40 sets the null hypothesis value — R tests whether the true population mean equals 40.
One Sample t-test
data: hrs_clean$hrs1
t = 5.0511, df = 1899, p-value = 0.0000004813
alternative hypothesis: true mean is not equal to 40
95 percent confidence interval:
41.01450 42.30234
sample estimates:
mean of x
41.65842 The sample mean hours worked per week was 41.66 hours. A one-sample t-test showed this is significantly different from 40 hours (\(p\) < 0.001). We reject \(H_0\); we accept \(H_1\): U.S. adults in this sample work significantly more than a standard 40-hour week.
The 95% CI [41.01, 42.3] does not contain 40 — this is the CI equivalent of rejecting \(H_0\) at \(\alpha = 0.05\).

Test 2: Two-Sample t-Test
Running example: Do union members work a different number of hours per week than non-members?
- \(H_0\): \(\mu_{\text{union}} = \mu_{\text{non-union}}\) (equivalently: \(\mu_1 - \mu_2 = 0\))
- \(H_1\): \(\mu_{\text{union}} \neq \mu_{\text{non-union}}\)
Under \(H_0\), the test statistic:
\[t = \frac{\bar{x}_1 - \bar{x}_2}{SE_{\text{diff}}} \quad \text{where} \quad SE_{\text{diff}} = \sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}\]
Degrees of freedom: \(df \approx n_1 + n_2 - 2\) (R uses Welch’s correction, adjusting df when variances differ)
Welch Two Sample t-test
data: union_hrs and nonunion_hrs
t = 1.8535, df = 316.26, p-value = 0.06475
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.1122722 3.7619461
sample estimates:
mean of x mean of y
43.52284 41.69801 Union members worked an average of 43.52 hours per week, compared to 41.7 hours for non-members (difference = 1.82 hrs). A two-sample t-test showed this difference was not statistically significant (\(p\) = 0.065). We fail to reject \(H_0\): we cannot conclude union members work different hours than non-members.
The 95% CI on the difference [-0.11, 3.76] includes 0 — consistent with failing to reject \(H_0\) at \(\alpha = 0.05\).

Test 3: Testing a Proportion
We follow the same set up, but use a slightly different distribution.
Running example: Is the proportion of U.S. adults who are union members equal to 20%?
- \(H_0: \pi = 0.20\)
- \(H_1: \pi \neq 0.20\) (two-tailed)
- Significance level: \(\alpha = 0.05\)
Under \(H_0\), the sampling distribution of \(\hat{p}\) is approximately:
\[\hat{p} \sim N\!\left(\pi_0,\; SE_0\right) \quad \text{where} \quad SE_0 = \sqrt{\frac{\pi_0(1-\pi_0)}{n}}\]
Step 1: Compute the standard error under \(H_0\):
\[SE_0 = \sqrt{\frac{\pi_0(1-\pi_0)}{n}} = \sqrt{\frac{0.20 \times 0.80}{n}}\]
Step 2: Compute the z-statistic:
\[z = \frac{\hat{p} - \pi_0}{SE_0}\]
Step 3: Calculate the p-value:
| Test | R code |
|---|---|
| Two-tailed | 2 * pnorm(-abs(z)) |
| One-tailed (upper) | pnorm(-abs(z)) |
prop.test() handles the SE and test statistic automatically — just supply the count of successes, the sample size, and the null value.
1-sample proportions test without continuity correction
data: x out of n, null probability 0.2
X-squared = 62.306, df = 1, p-value = 0.000000000000002941
alternative hypothesis: true p is not equal to 0.2
95 percent confidence interval:
0.1150532 0.1445757
sample estimates:
p
0.1290973 The sample union membership rate was 0.129 (12.9%). A proportion test showed this was significantly different from 20% (\(p\) = 0). We reject \(H_0\); we accept \(H_1\).
The 95% CI [0.115, 0.145] does not contain 0.20 — the null value falls entirely outside the plausible range for the true proportion, confirming we reject \(H_0\).
