Week 8
Sociology 106: Quantitative Sociological Methods
March 10, 2026
Visualizing Bias and Efficiency

Remember: bias relates to accuracy, efficiency relates to precision
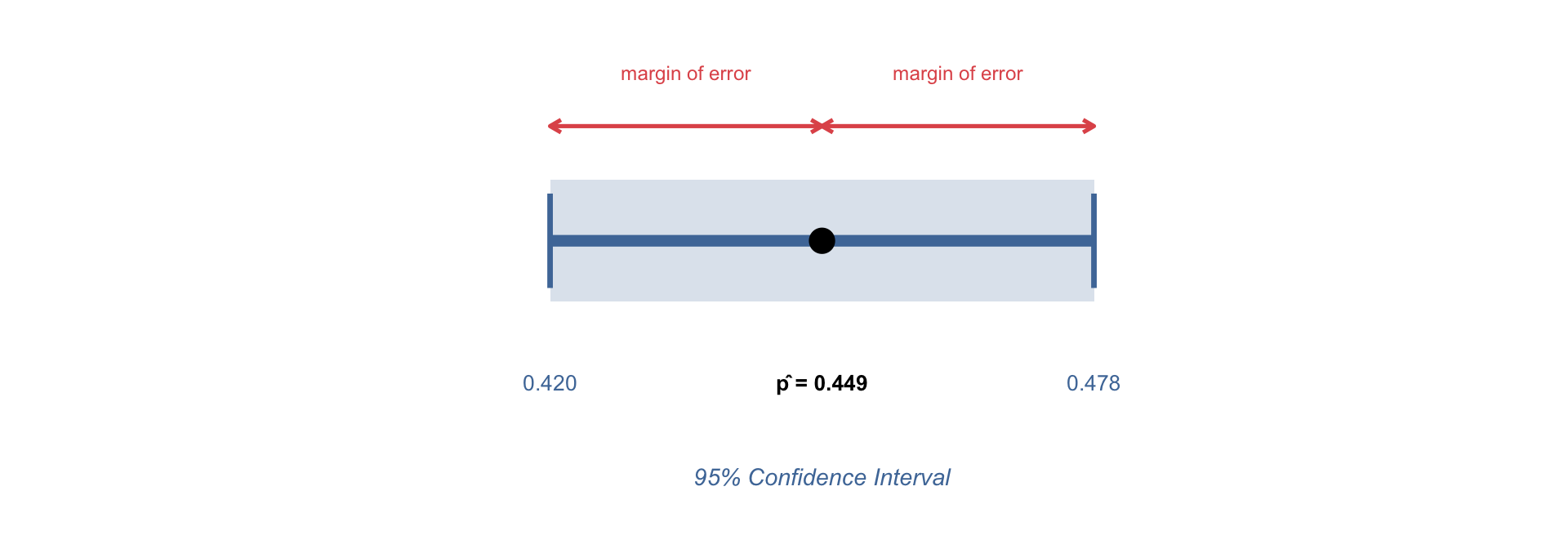
Confidence Level and Margin of Error
The confidence level is the probability that a confidence interval contains the true population parameter
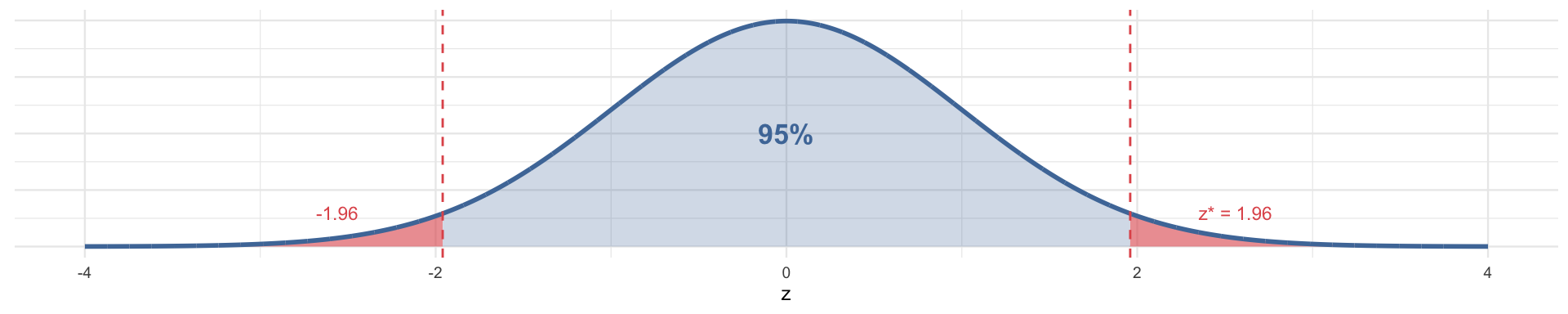
- Most common: 95% — if we repeated this study 100 times, 95 of our intervals would contain the true \(\pi\)
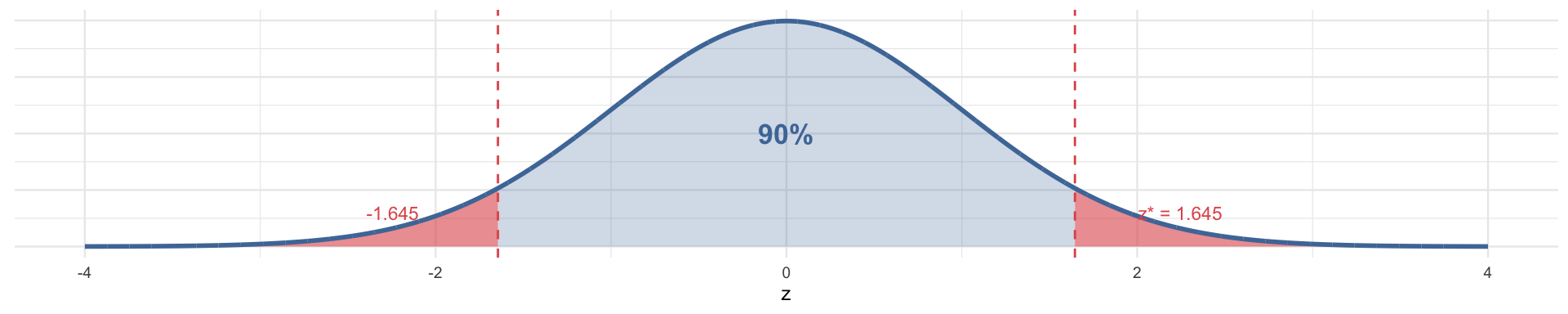
- Also used: 90%, 99%, 99.9%
The margin of error is how far the CI extends in each direction from the point estimate:
\[\text{Margin of Error} = z^* \times SE(\hat{p})\]
- Expressed as \(\pm\) around the point estimate
- Example from the news: Candidate A is expected to receive 41% ± 3% of the vote — the margin of error is ±3 percentage points
\[\hat{p} \pm \underbrace{z^* \times SE(\hat{p})}_{\text{margin of error}} = \left[\hat{p} - z^* \cdot SE,\;\; \hat{p} + z^* \cdot SE\right]\]
| Piece | Meaning |
|---|---|
| \(\hat{p}\) | Point estimate — center of the interval |
| \(z^*\) | Critical value — from the standard Normal for our confidence level |
| \(SE(\hat{p})\) | Standard error — how uncertain is \(\hat{p}\)? |
| \(z^* \times SE\) | Margin of error — how wide is each side? |
The critical value \(z^*\) depends on the confidence level. These are the ones you’ll use most often:
| Confidence level | \(\alpha\) (= 1 − conf.) | \(\alpha/2\) (each tail) | \(z^*\) |
|---|---|---|---|
| 90% | 0.10 | 0.05 | 1.645 |
| 95% | 0.05 | 0.025 | 1.960 |
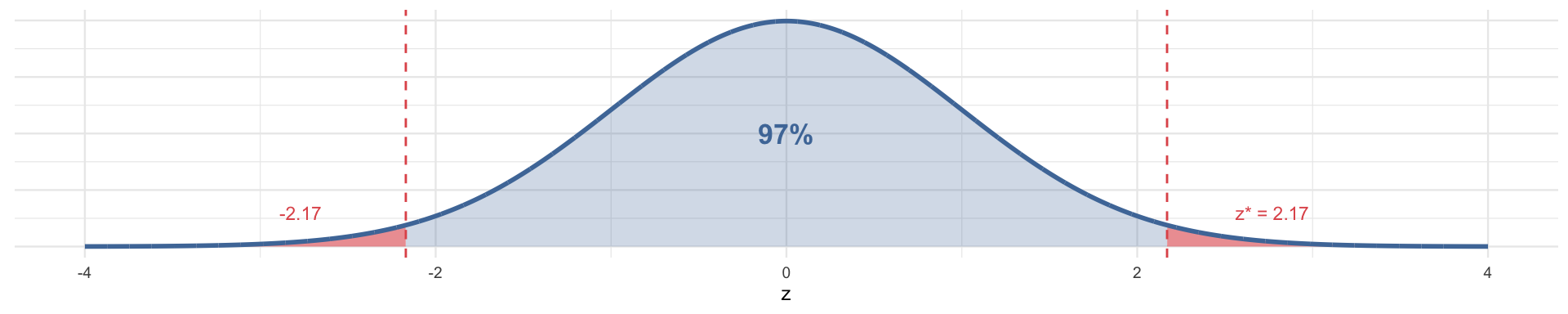
| 97% | 0.03 | 0.015 | 2.170 |
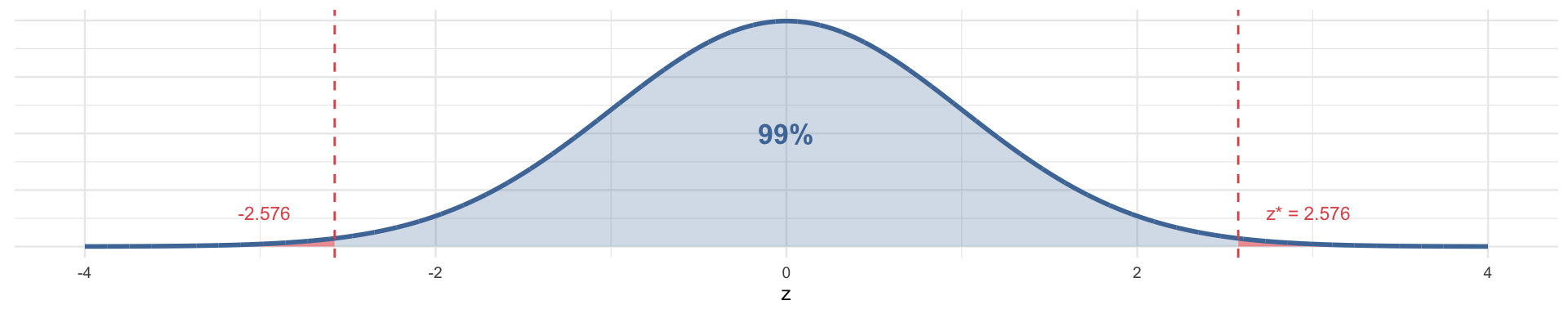
| 99% | 0.01 | 0.005 | 2.576 |
Finding Critical Values in R
To build a CI, we need \(z^*\) — the number of standard errors to extend in each direction so the interval captures the central X% of the Normal distribution. We find \(z^*\) using qnorm(), which returns the z-score that cuts off a given tail probability.
The logic: for a 95% CI, we want 2.5% in each tail → we ask for the z that satisfies \(P(Z > z) = 0.025\):
One vs. Two-Tailed Tests
When we test for differences, we can test in one or both directions:
A one-tailed test checks for a significant effect in one specific direction (greater than or less than)
- Use when theory predicts the direction of the effect
- All 5% significance is concentrated in one tail — easier to reject
Example: Is the proportion of Americans willing to pay for the environment greater than 40%?
A two-tailed test looks for any significant difference in either direction
- Use when theory does not predict the direction
- 5% significance split equally: 2.5% in each tail — more conservative
- More common in social science research
Example: Is the proportion of Americans willing to pay for the environment different from 40%?
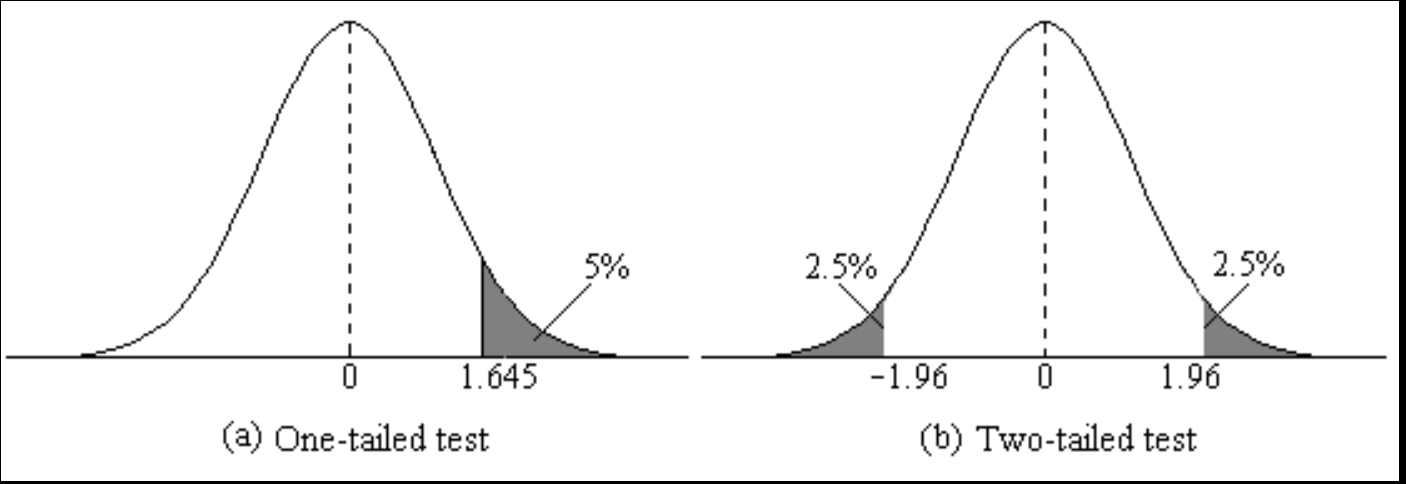
- One-tailed: rejection region entirely on one side
- Two-tailed: rejection region split equally — requires a larger test statistic to reject
Trade-offs in Confidence Intervals
As confidence level increases → margin of error increases
- More confidence requires a larger \(z^*\)
- Wider interval → we “catch” the parameter more often, but learn less about exactly where it is
| Confidence level | \(z^*\) | Margin of error (GSS example) |
|---|---|---|
| 90% | 1.645 | ±0.024 |
| 95% | 1.960 | ±0.029 |
| 99% | 2.576 | ±0.038 |
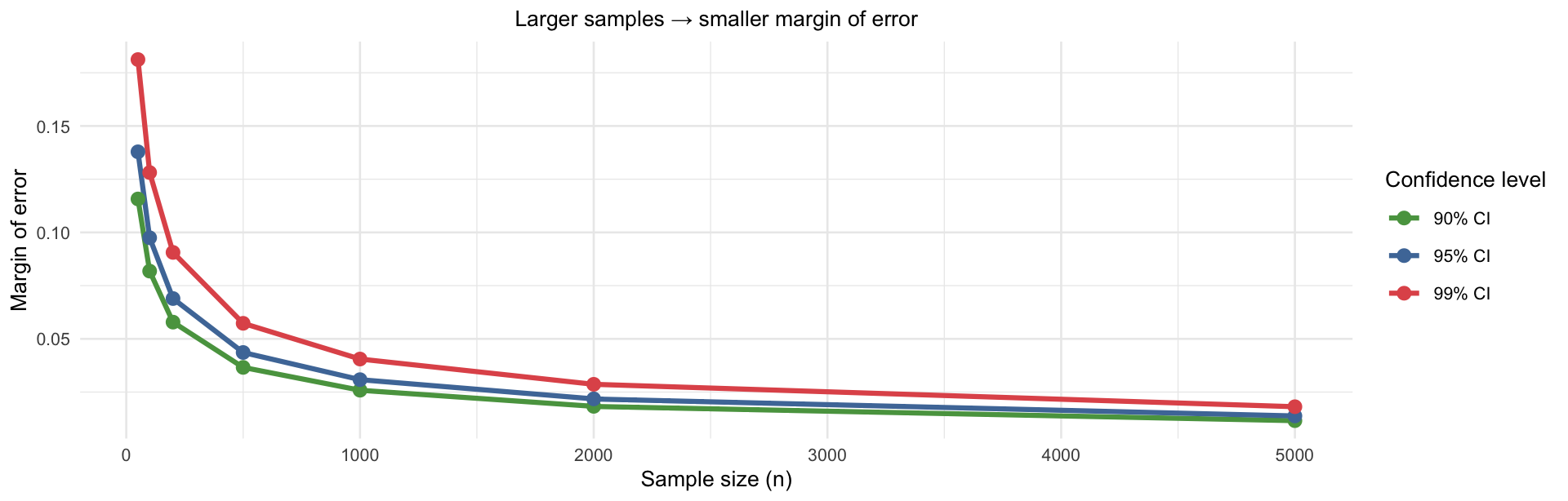
As sample size increases → margin of error decreases
\[ME = z^* \times \sqrt{\frac{\hat{p}(1-\hat{p})}{n}} \quad \longrightarrow \quad \text{larger } n \Rightarrow \text{ smaller } ME\]
| Sample size \(n\) | SE | Margin of error (95%) |
|---|---|---|
| 100 | 0.050 | ±0.098 |
| 500 | 0.022 | ±0.044 |
| 1154 | 0.015 | ±0.029 |
Quadrupling the sample size halves the margin of error
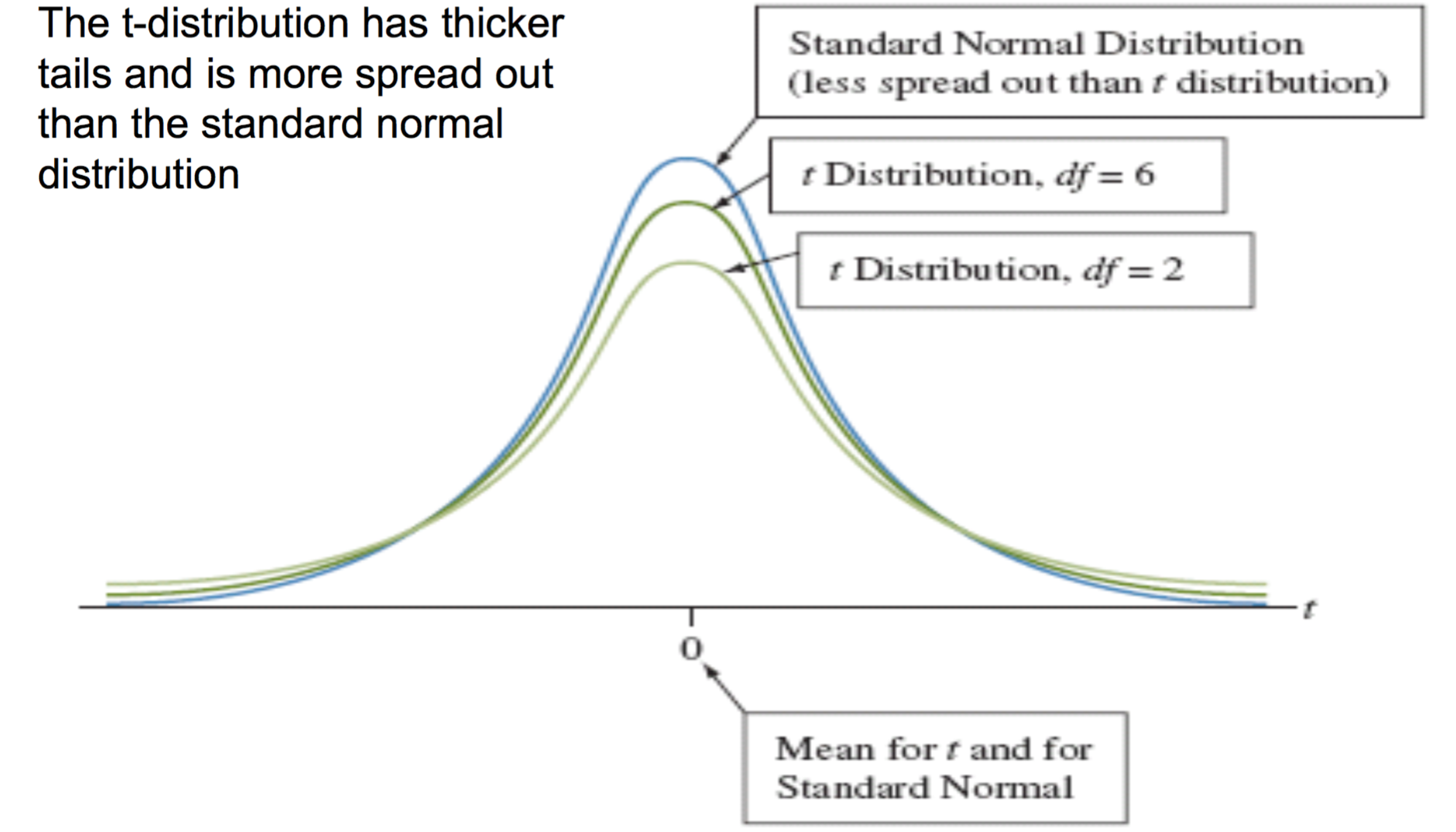
Properties of the t-Distribution
Key properties:
- With small df (small samples): much fatter tails than Normal
- With df > 100: practically indistinguishable from \(N(0,1)\)
- For small samples, the variable must be approximately Normal in the population
Consequence for CIs:
- The t-critical value \(t^*\) is always ≥ \(z^*\)
- Small samples → larger \(t^*\) → wider CI (reflecting genuine extra uncertainty)
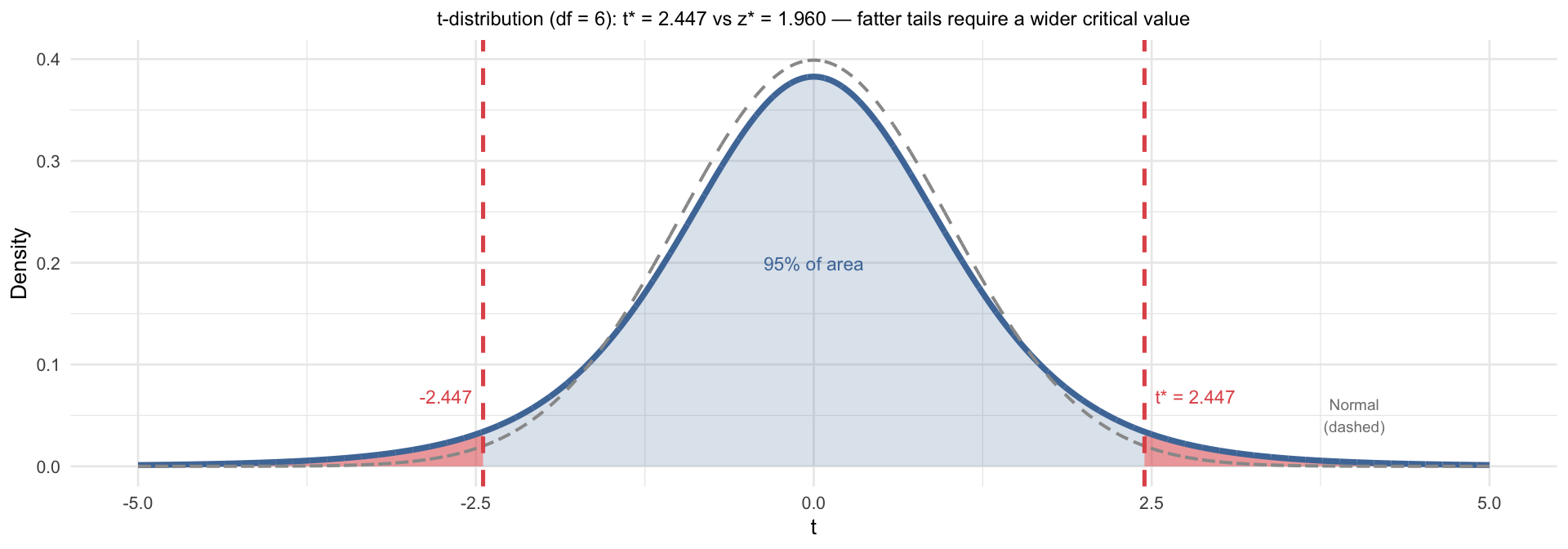
Worked Example: Heights
Study: 7 American adults from a simple random sample. Average height: 67.2 in, SD: 3.9 in. What is the 95% CI for the average height of all American adults?
Identify the values:
| Quantity | Value |
|---|---|
| Sample mean \(\bar{x}\) | 67.2 inches |
| Sample std dev \(s\) | 3.9 inches |
| Sample size \(n\) | 7 |
| Degrees of freedom | \(df = n - 1 = 6\) |
Find the critical t-value for a 95% CI with \(df = 6\):
Compare to \(z^* = 1.960\) — noticeably larger with a small sample. This is why we use the t-distribution: with only 7 observations, we need a wider interval to achieve true 95% coverage.
Calculate the standard error:
\[SE(\bar{x}) = \frac{s}{\sqrt{n}} = \frac{3.9}{\sqrt{7}} = \frac{3.9}{2.646} = 1.474 \text{ inches}\]
Compute and interpret the confidence interval:
\[\bar{x} \pm t^* \times SE = 67.2 \pm 2.447 \times 1.474 = 67.2 \pm 3.6 = [63.6,\; 70.8]\]
Interpretation: We are 95% confident the average height of all American adults is between 63.6 and 70.8 inches
Using CIs to Compare Groups
The same CI logic applies separately to subgroups — useful when your research question involves comparing populations:
Calculate a CI for each group independently, then compare:
- If the intervals do not overlap → preliminary evidence of a real difference between the group means
- If they do overlap → the observed difference may just be sampling variability
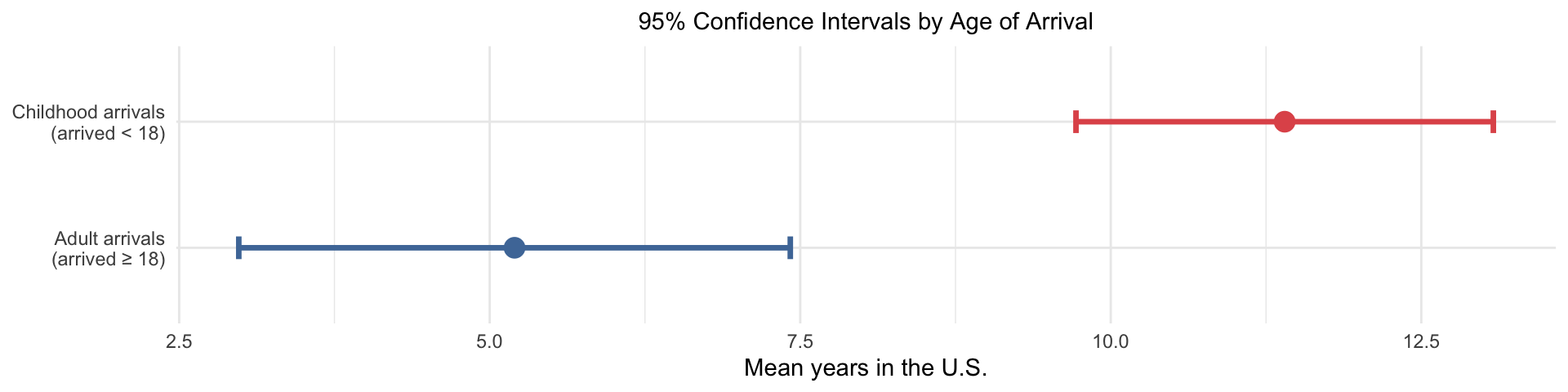
Do childhood and adult arrivals differ in years spent in the U.S.?
| Group | \(n\) | \(\bar{x}\) | \(s\) | 95% CI |
|---|---|---|---|---|
| Childhood arrivals (arrived < 18) | 20 | 11.4 | 3.6 | [9.7, 13.1] |
| Adult arrivals (arrived ≥ 18) | 15 | 5.2 | 4.0 | [3.0, 7.4] |
The intervals do not overlap → childhood arrivals have spent meaningfully more time in the U.S.