Week 7
Sociology 106: Quantitative Sociological Methods
March 3, 2026
Sampling from a Population
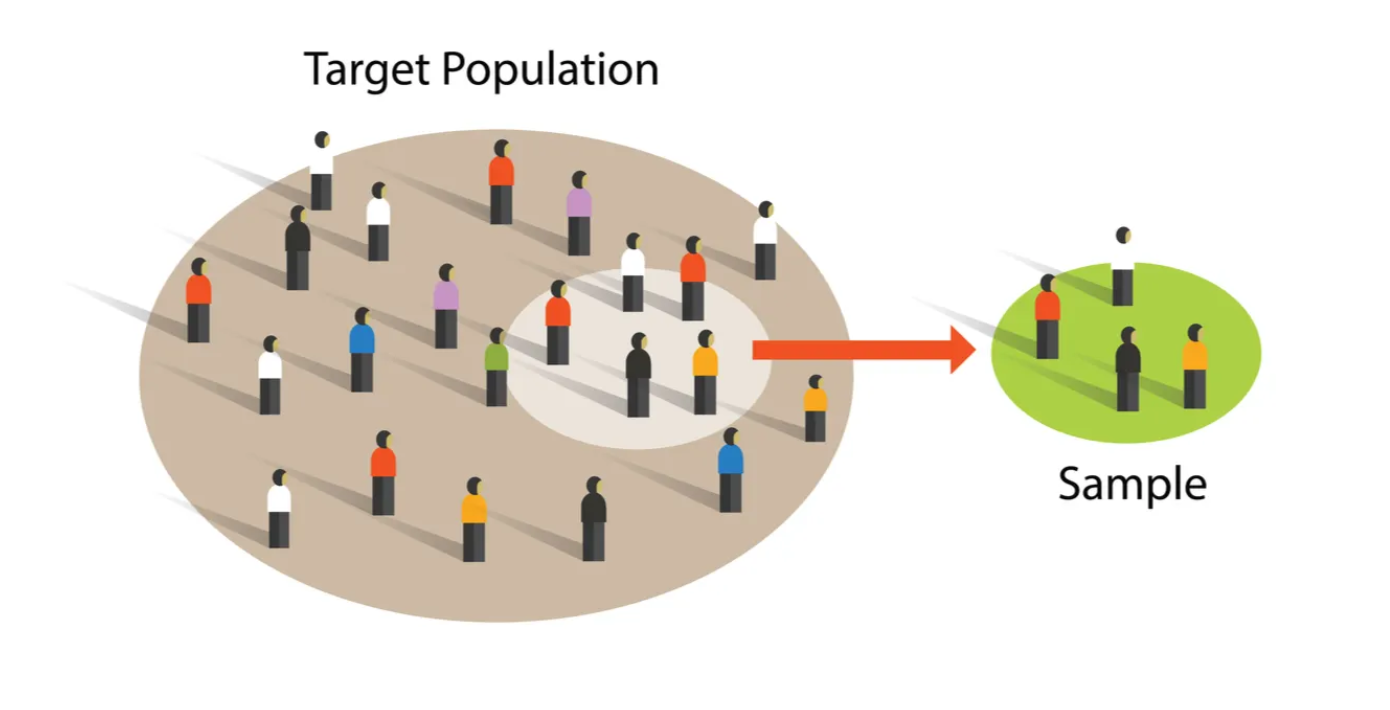
Start with a population — every individual you want to study. In our running example, this is all 1.45 million residents of Philadelphia in 1997. Since you can’t talk to everyone, you have to take a representive sample, that you hope will approximate your population.
Sampling from a Population
A sample is drawn from the population — the individuals we actually observe. The 262 drivers stopped by police are our sample, far smaller than the full population.
Sampling from a Population
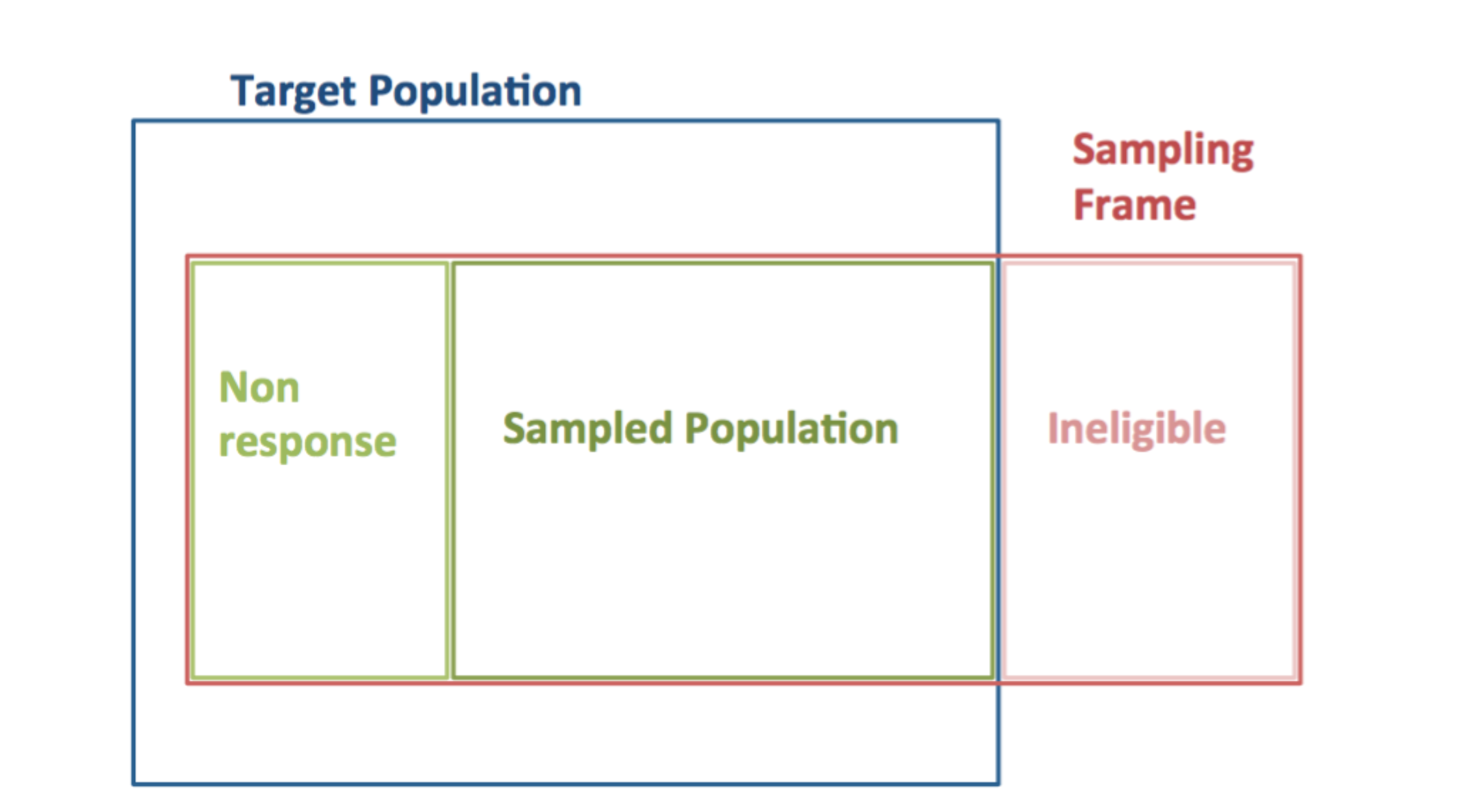
Key question: is our sample representative? Does it reflect the composition of the population? This depends entirely on the sampling design — random samples are representative; convenience samples often are not.
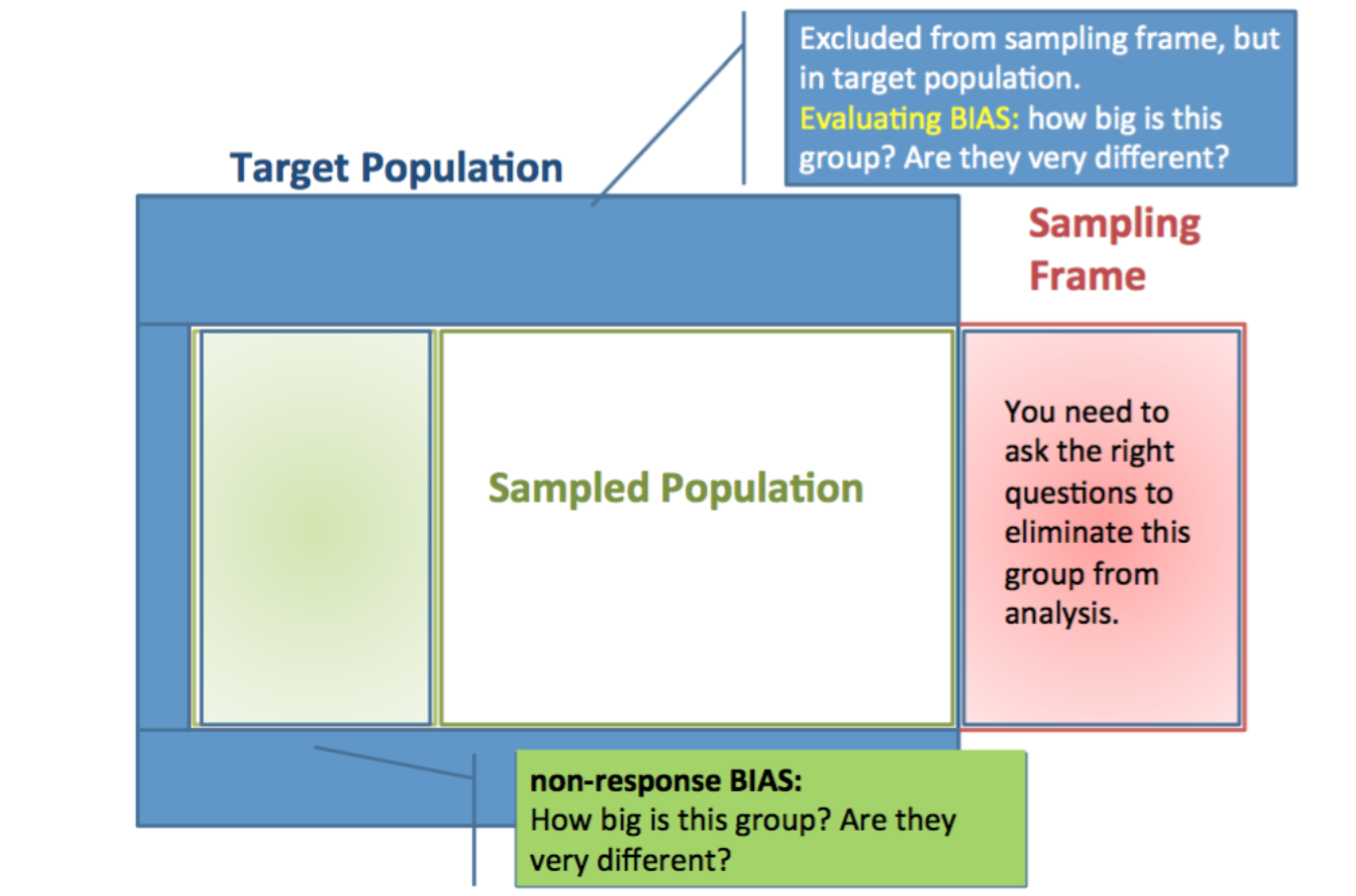
Types of Sampling Designs
Simple random sample: Use a random number generator to select from a population list
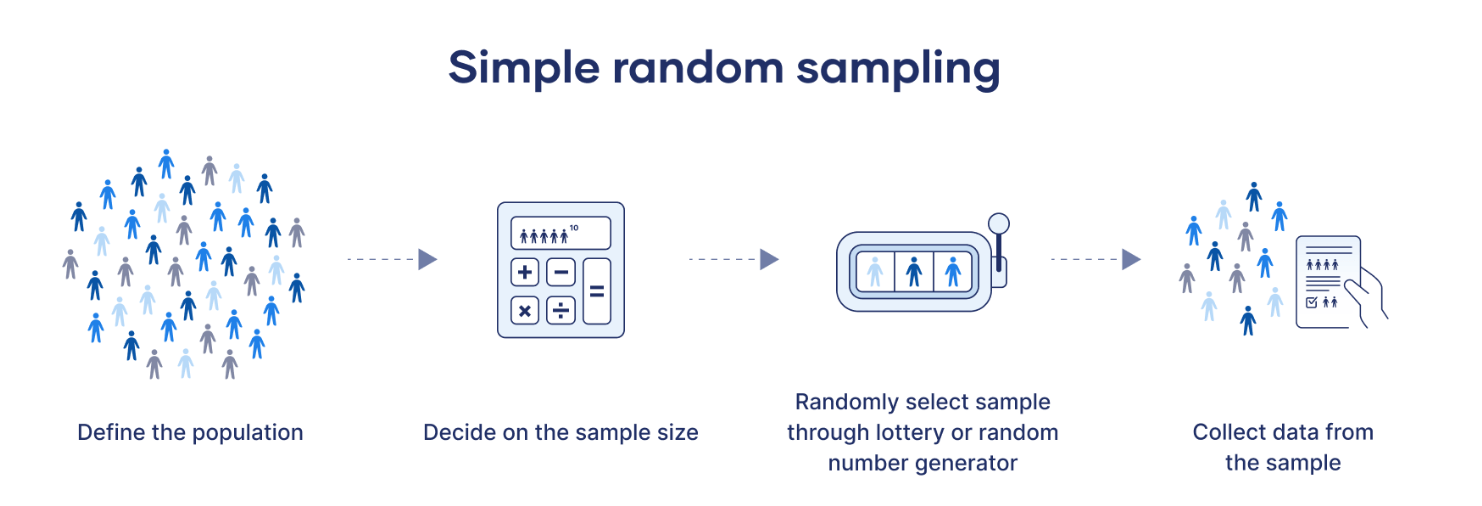
Stratified random sample: Divide population into homogenous groups (strata), then randomly sample within each stratum
- Generally improves precision
- Can over-sample smaller strata (e.g., minority groups) to make inferences within those groups
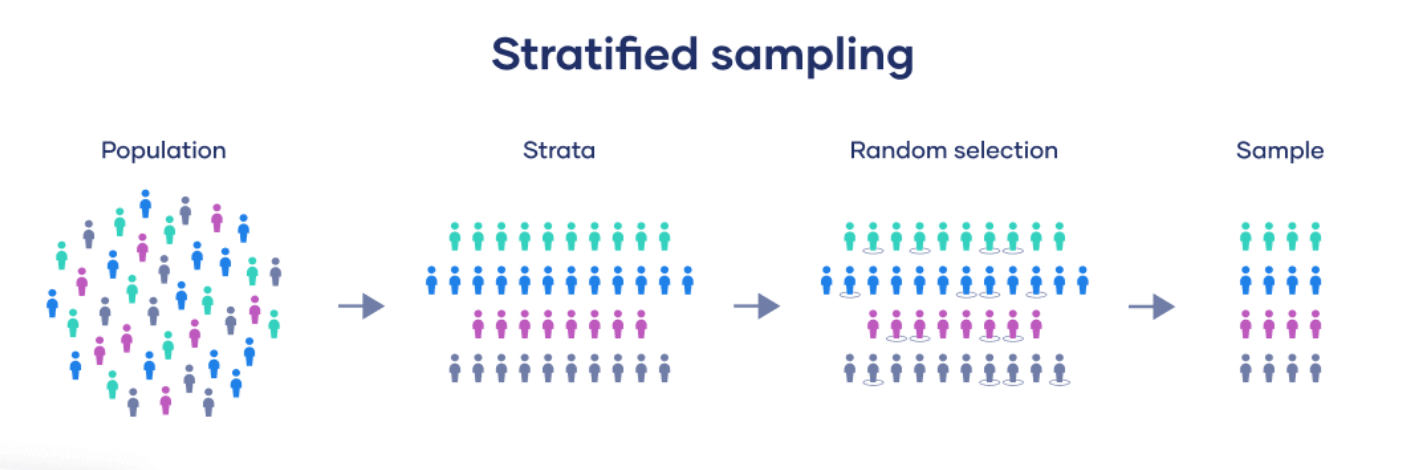
Cluster sampling:
- Create subpopulations (clusters)
- Randomly select a sample of clusters
- Randomly select units within sampled clusters
Stratified vs. Cluster Sampling
Key difference: cluster sampling selects only some groups; stratified sampling samples from all strata.
When to use which:
- Cluster: use when sampling individuals directly is costly (e.g., 4th graders in California – schools)
- Stratified: use when you need better representation of known subgroups (e.g., GPA by major – class year)
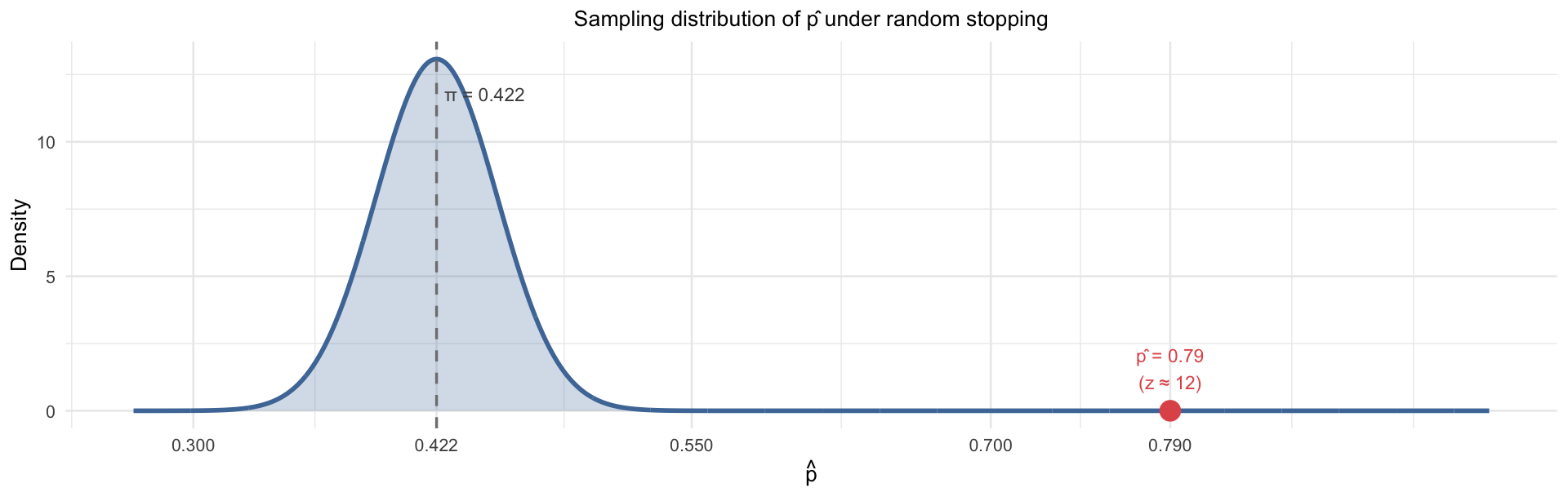
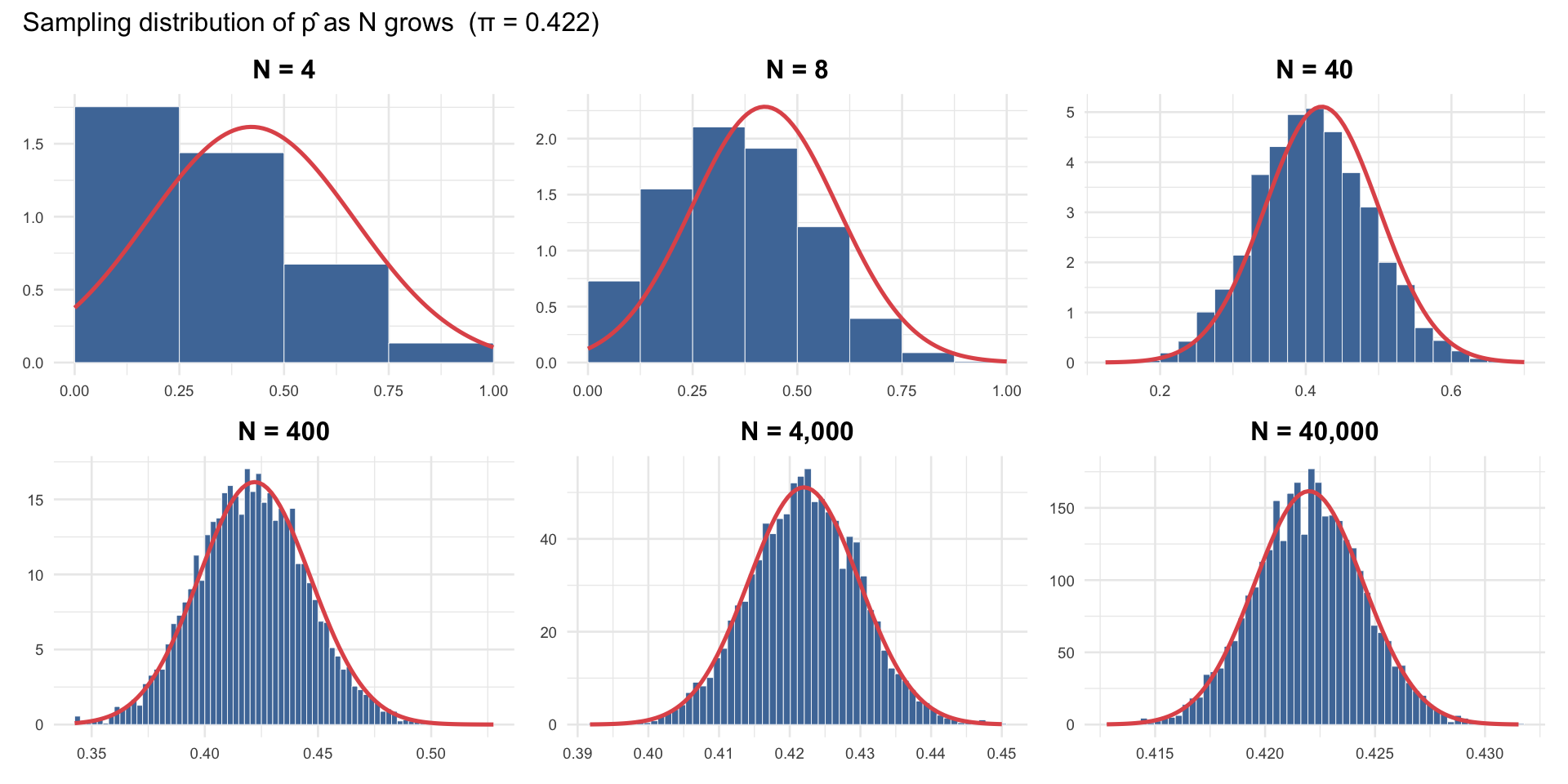
Visualizing the Sampling Distribution
As \(N\) increases, \(\hat{p}\) becomes tighter and more bell-shaped — the Central Limit Theorem in action:
Sampling Distribution of the Mean
For a random sample of size \(n\) from a population with mean \(\mu\) and standard deviation \(\sigma\):
\[\mu_{\bar{x}} = \mu \qquad \text{(sample mean is unbiased)}\]
\[SE(\bar{x}) = \frac{\sigma}{\sqrt{n}} \qquad \text{(precision increases with sample size)}\]
Doubling \(n\) cuts the SE by a factor of \(\sqrt{2}\) — not 2. Precision is expensive!
The problem: You manage a pizza restaurant and want to estimate your true average daily sales. You know from years of records that daily sales average \(\mu = \$900\) with a standard deviation of \(\sigma = \$300\) — but sales fluctuate day to day. If you observe only \(n = 7\) days, how close will your sample mean be to the true average?
\[SE(\bar{x}) = \frac{\$300}{\sqrt{7}} \approx \$113\]
A 7-day average will typically be within \(\pm\$226\) (2 SEs) of the true mean — so your estimate could easily be off by over $200. Observing 28 days instead cuts the SE in half: \(\frac{\$300}{\sqrt{28}} \approx \$57\), giving a much more reliable estimate.
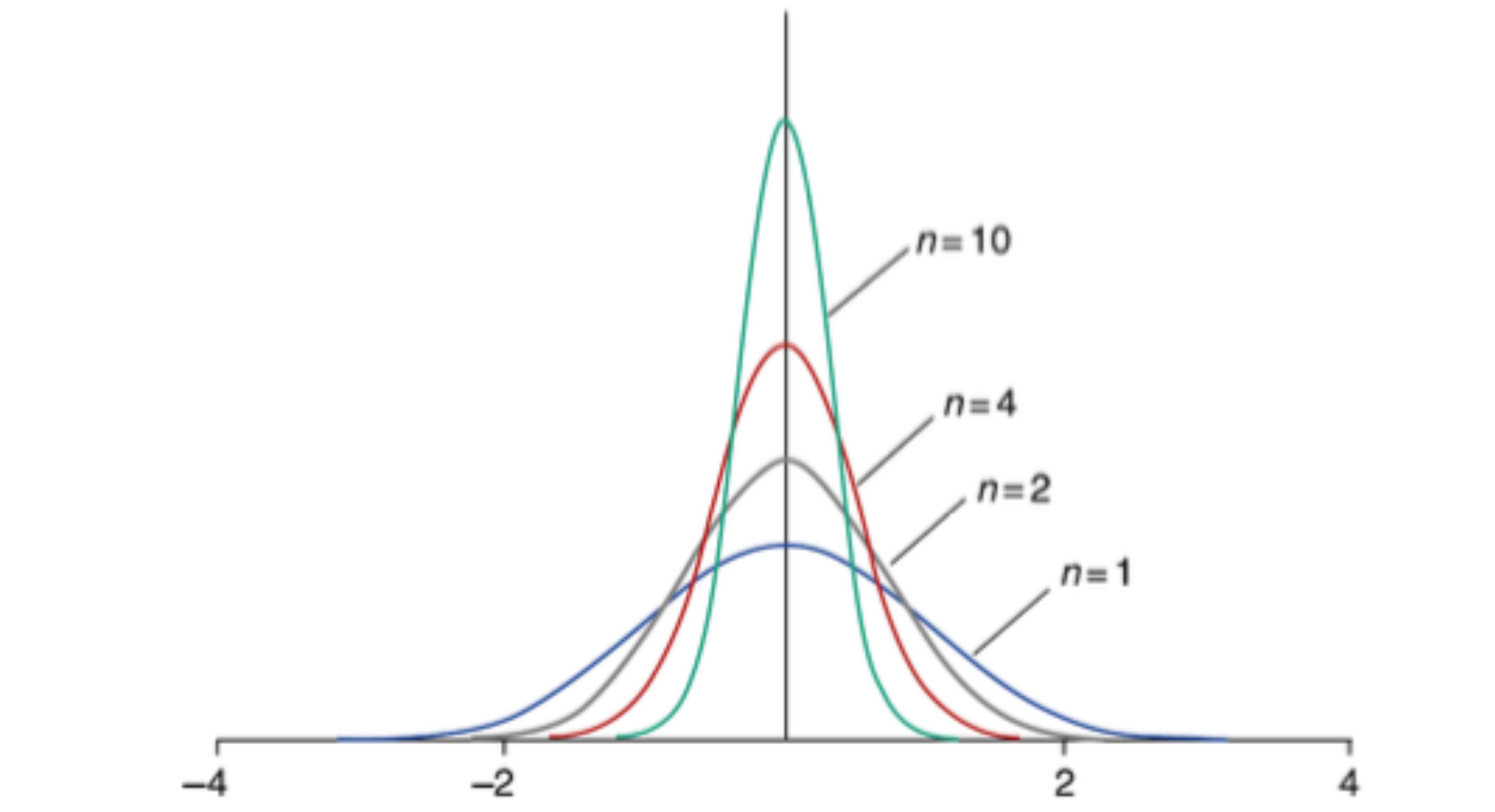
As \(n\) grows, the sampling distribution narrows around the true mean \(\mu\):
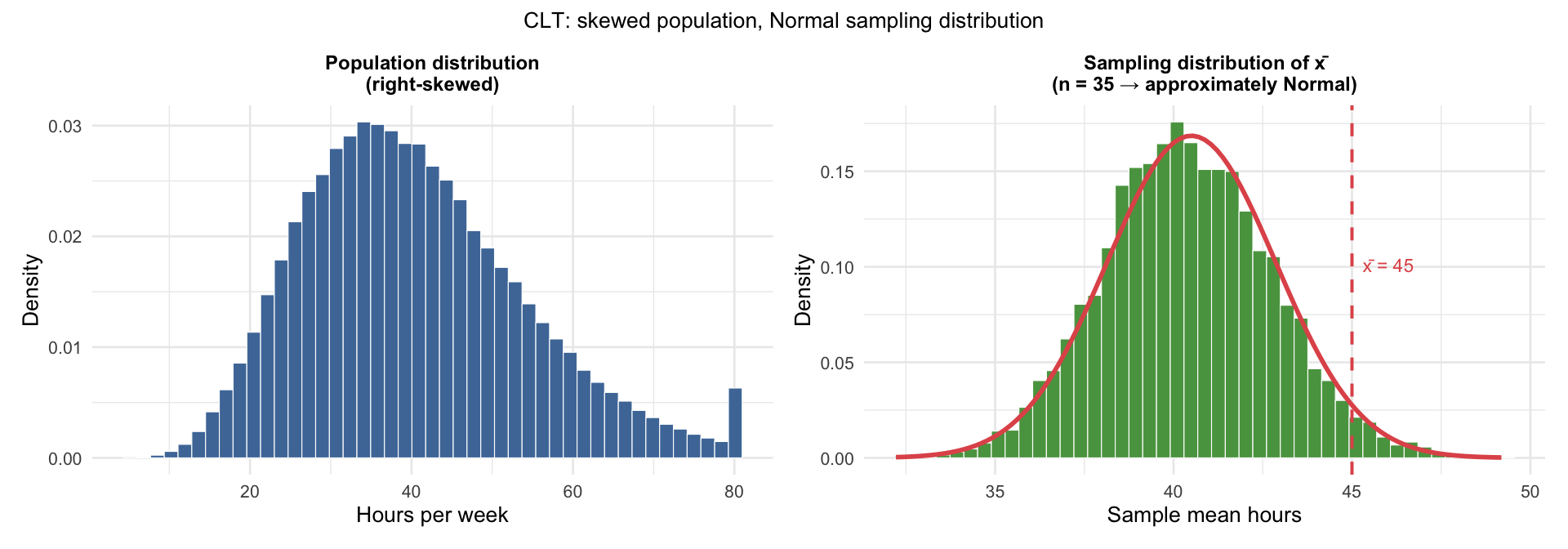
Weekly Work Hours: A Worked Example
GSS data show that among employed US adults, weekly work hours are right-skewed: \(\mu = 40.5\) hours, \(\sigma = 14\) hours.
A labor researcher samples \(n = 35\) workers at a specific company and finds a mean of 45 hours/week.
Question: If this company is typical of the US workforce, how unusual is a sample mean of 45 hours or higher?
The population is right-skewed — but \(n = 35 > 30\), so the CLT applies:
\[SE(\bar{x}) = \frac{\sigma}{\sqrt{n}} = \frac{14}{\sqrt{35}} \approx 2.37\]
\[\bar{x} \sim N(40.5,\; 2.37)\]
Even though individual work hours are skewed, the sample mean is approximately Normal.
Compute the probability in R
About 2.9% — if the company were typical, a mean this high would occur only 3% of the time by chance. This gives the researcher grounds to argue the company is unusually demanding.