Week 6
Sociology 106: Quantitative Sociological Methods
February 24, 2026
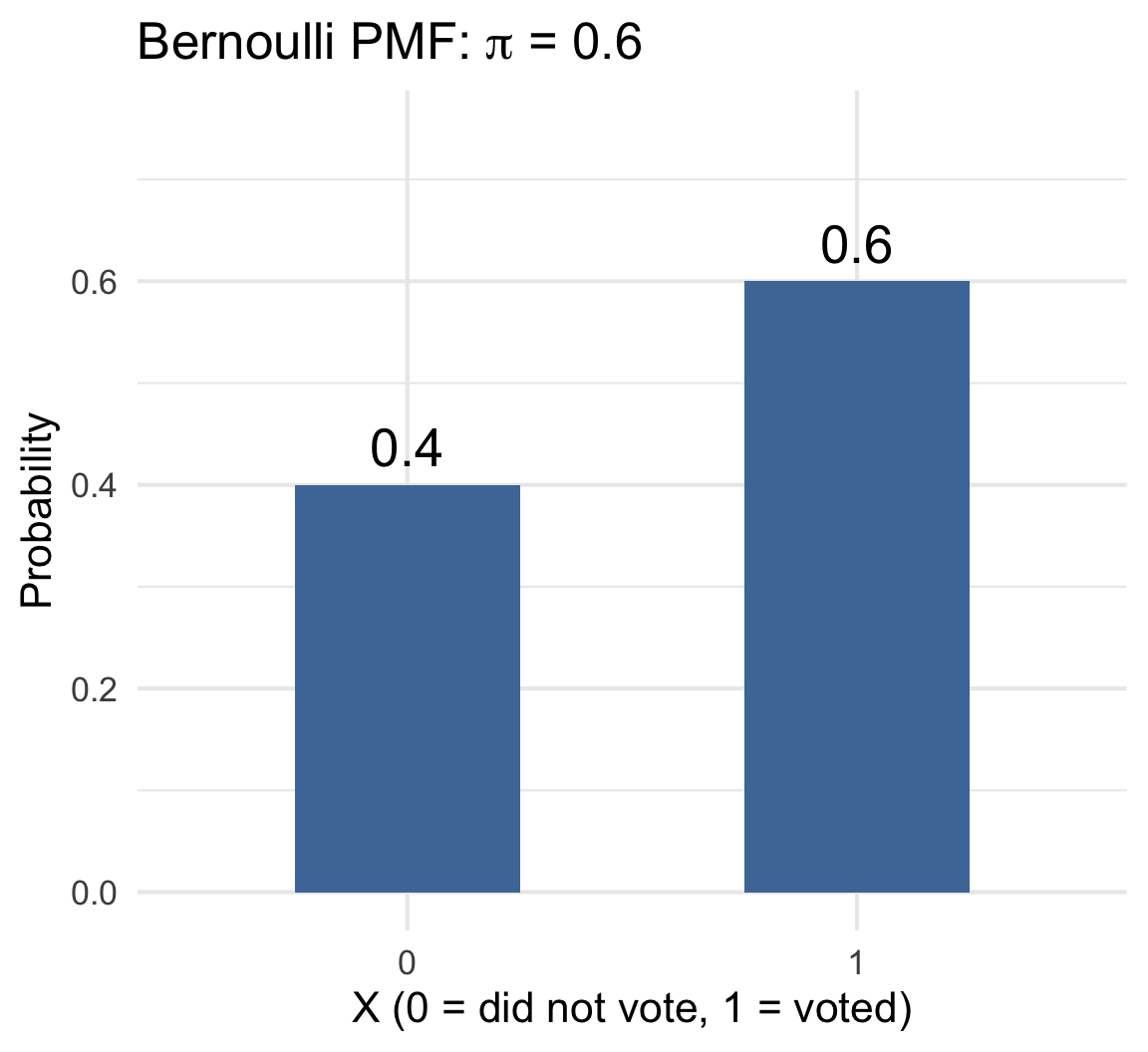
The Ladder: A Preview
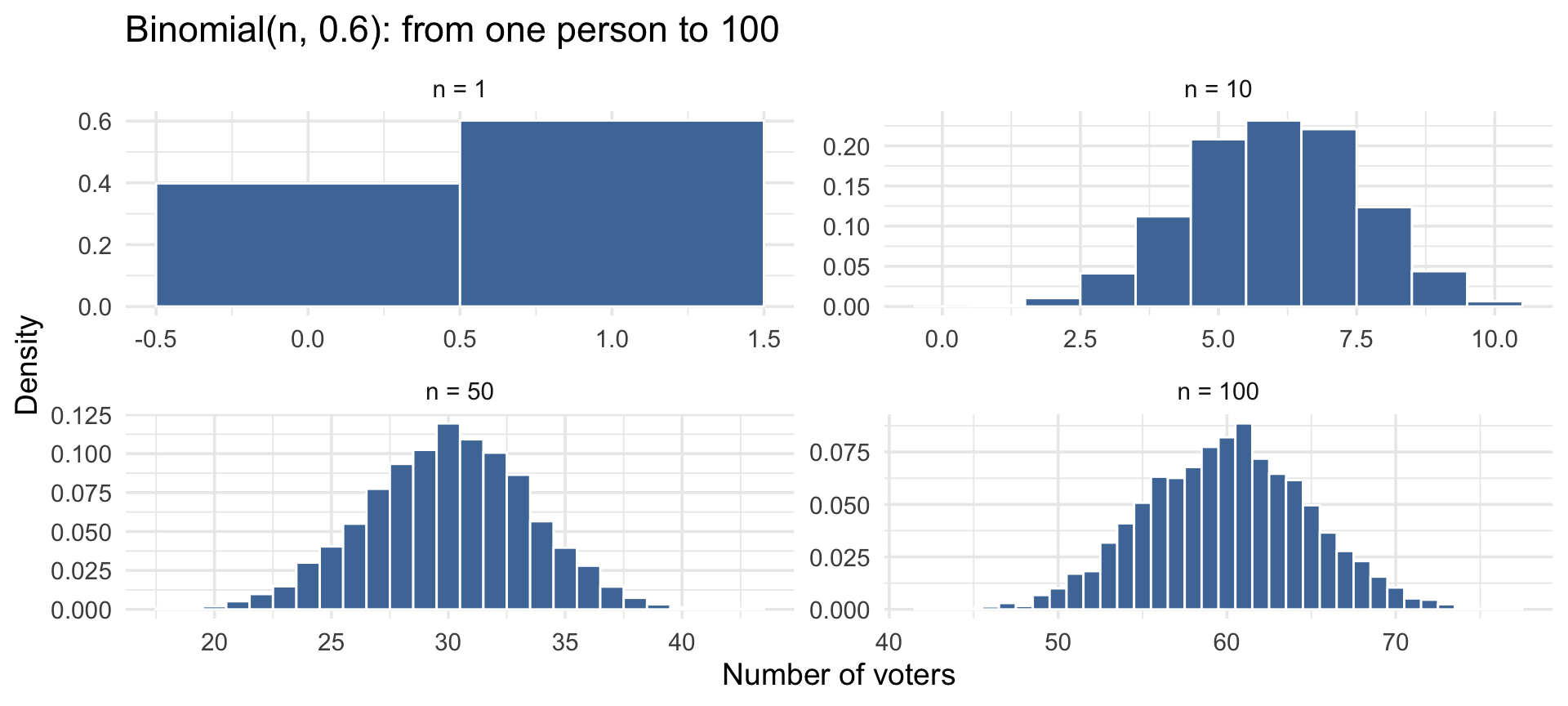
These three distributions are connected — each is the same voting question at a different scale:
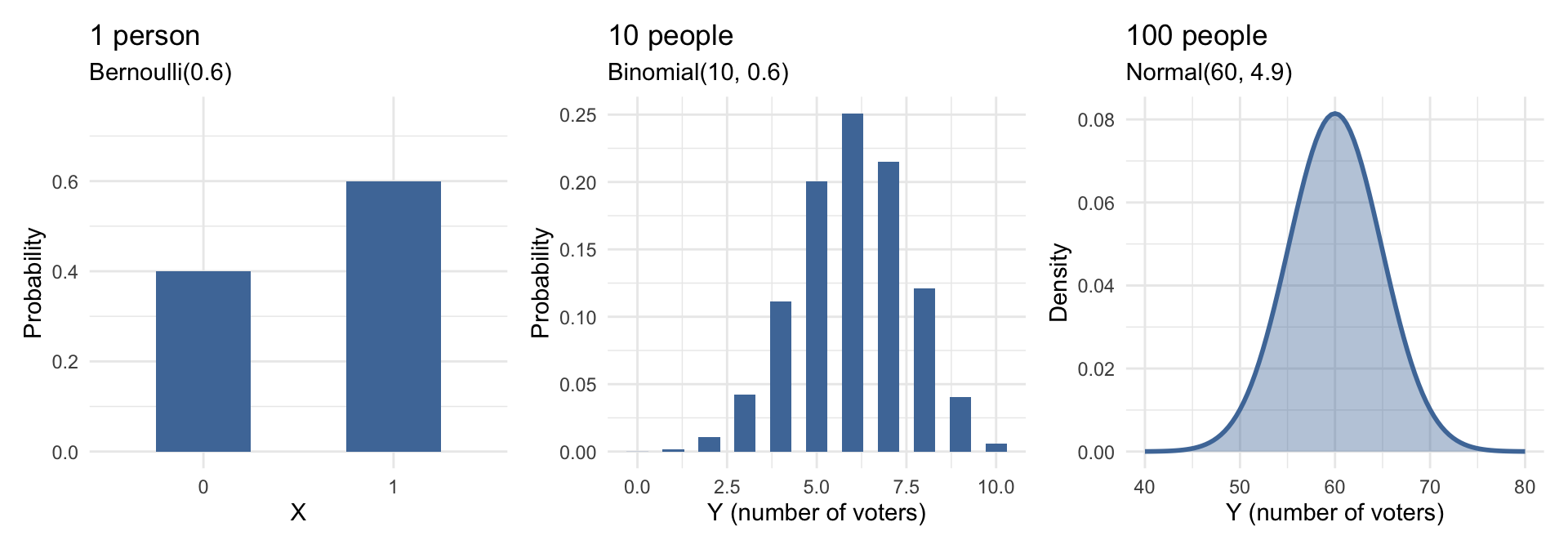
Same event, different scale: one person → a small sample → a large sample. We’ll build up to this step by step.
R Functions for Distributions
The suffix tells you the distribution: binom for Binomial, norm for Normal.
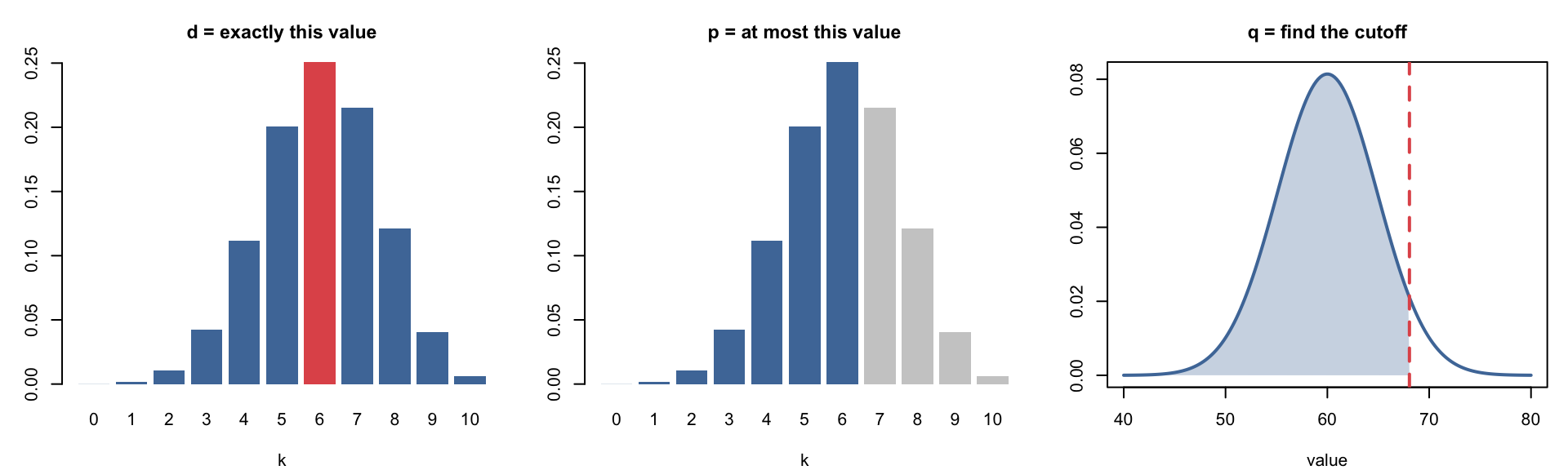
We’ll use each of these as we go. Keep this pattern in mind!
From Bernoulli to Binomial
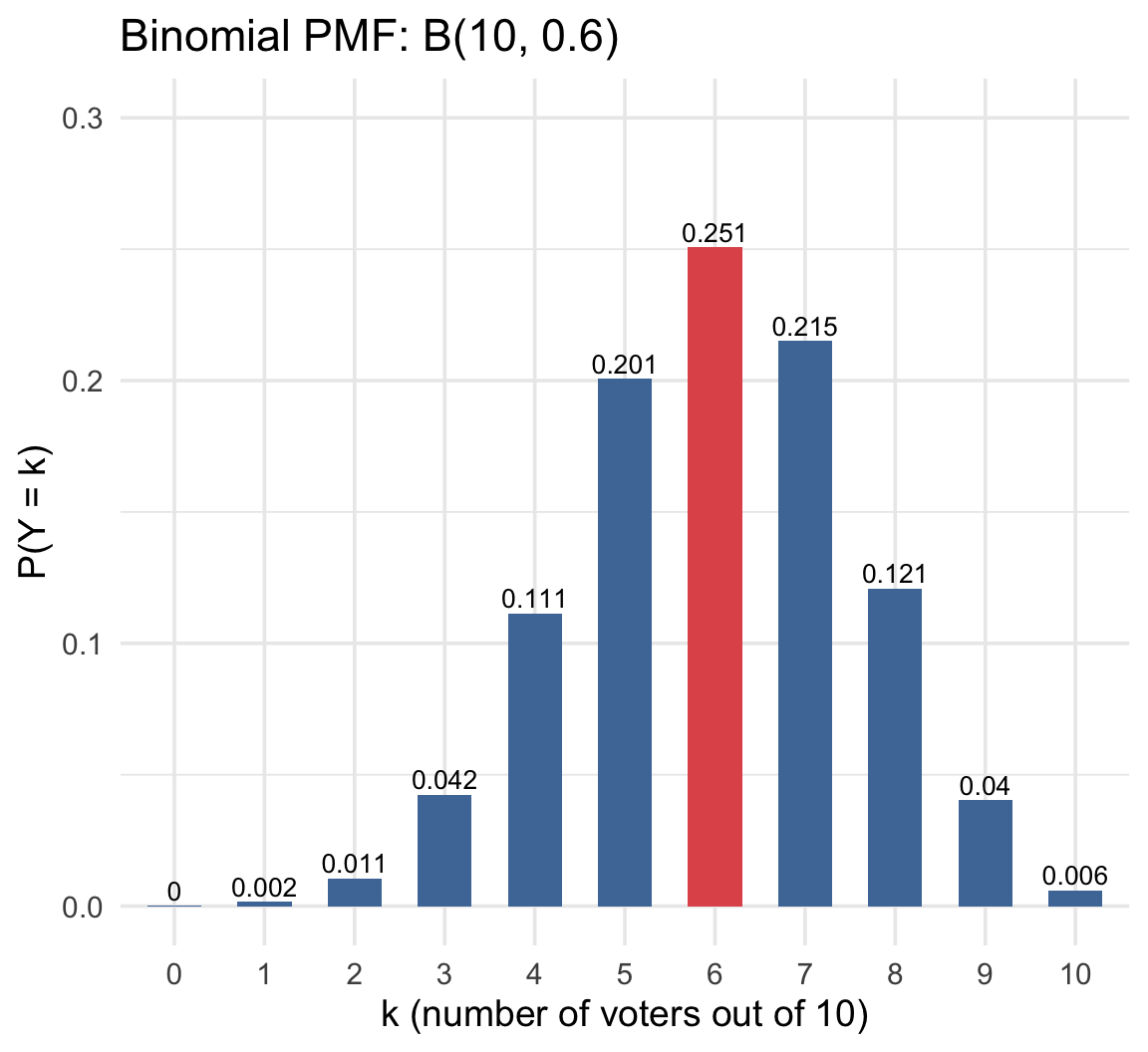
Now suppose we survey 10 people. Each person independently voted with probability 0.6.
What’s the probability that exactly 6 of the 10 voted? Or 4? Or 8?
We’re adding up 10 independent Bernoulli outcomes. The total, \(Y\), follows a Binomial distribution:
\[Y \sim \text{Binomial}(n=10, \; \pi=0.6)\]
The chart shows the probability of every possible outcome from 0 to 10 voters. The tallest bar (k = 6) is the single most likely result.
Practice: Binomial Probabilities
Let’s some scenarios that are similar to HW questions.
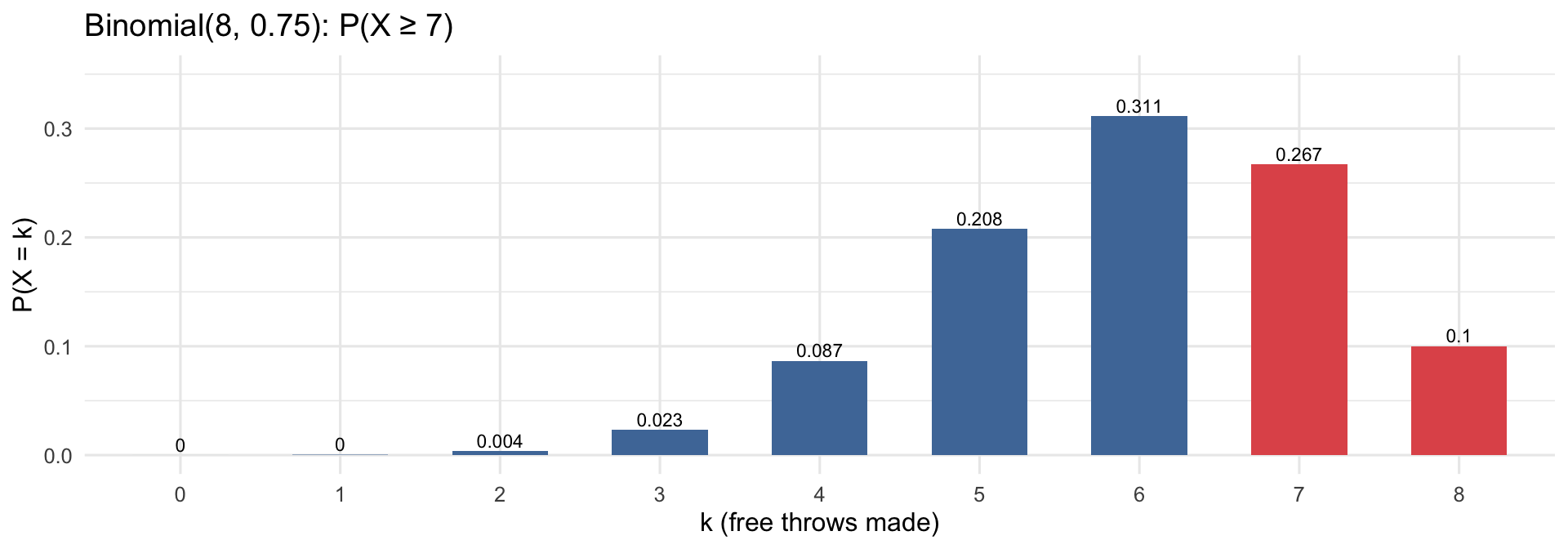
Lisa makes free throws 75% of the time and shoots 8 free throws at practice. What is the probability she makes at least 7?
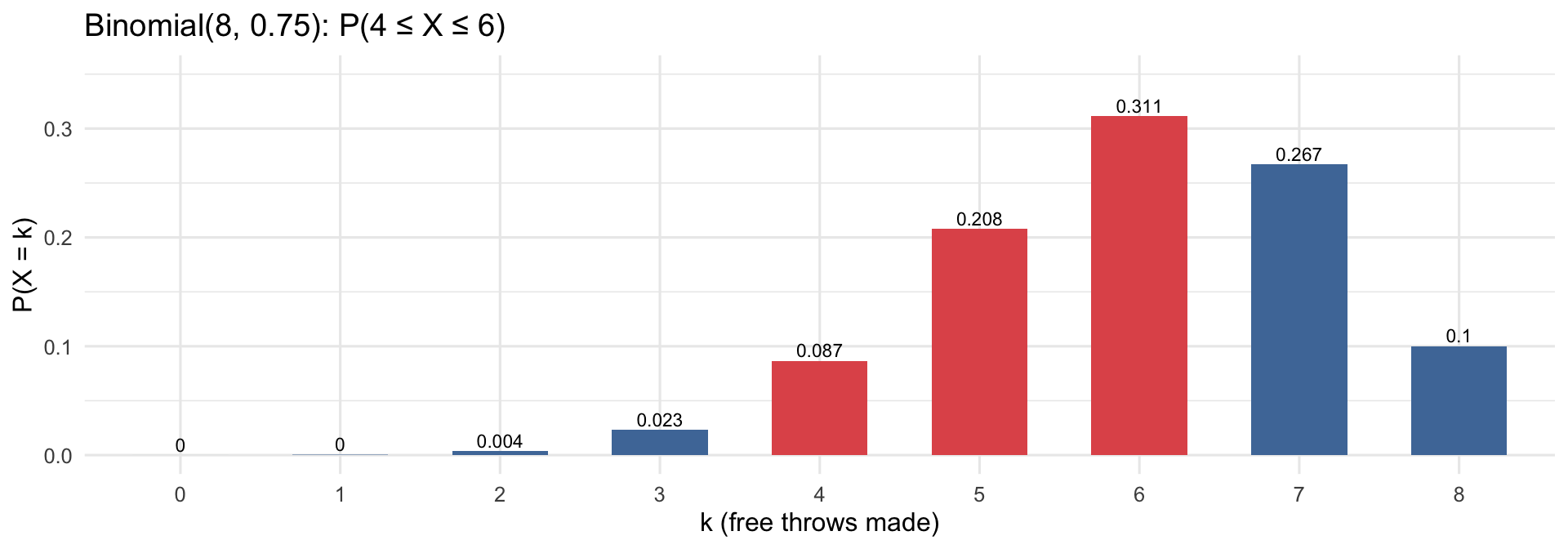
Same scenario: Lisa, n = 8, π = 0.75. What is the probability she makes between 4 and 6 free throws?
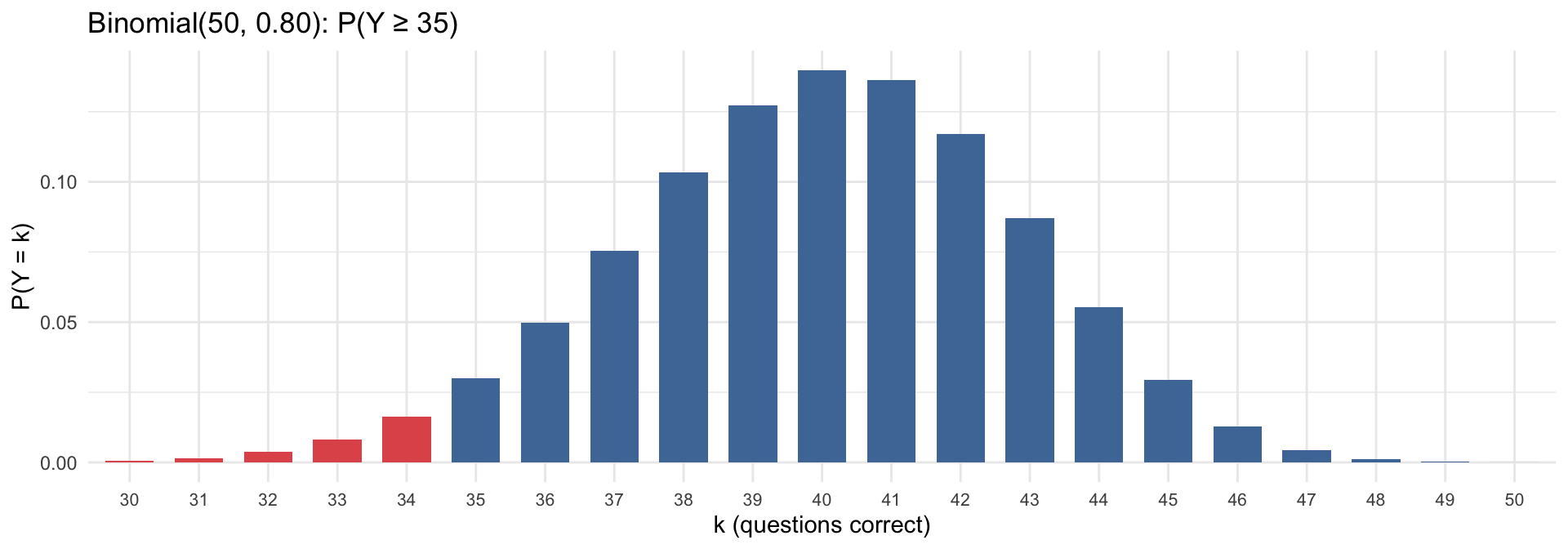
Why Binomial Starts Looking Normal
What if we surveyed 100 people instead of 10? As \(n\) grows, the Binomial distribution becomes smoother and starts to resemble a bell-shaped curve:
This is an early step toward central limit thinking: sums of many random components often look approximately Normal.
The Normal Distribution
For \(n = 100\) voters with \(\pi = 0.6\), the Binomial has:
- Mean: \(100 \times 0.6 = 60\) voters
- SD: \(\sqrt{100 \times 0.6 \times 0.4} \approx 4.9\) voters
What does SD = 4.9 mean? In most surveys of 100 people, the number of voters will be within about 5 of 60 — typically between 55 and 65.
Instead of computing exact Binomial probabilities across 101 values, we approximate with a Normal distribution: \(N(60, 4.9)\).
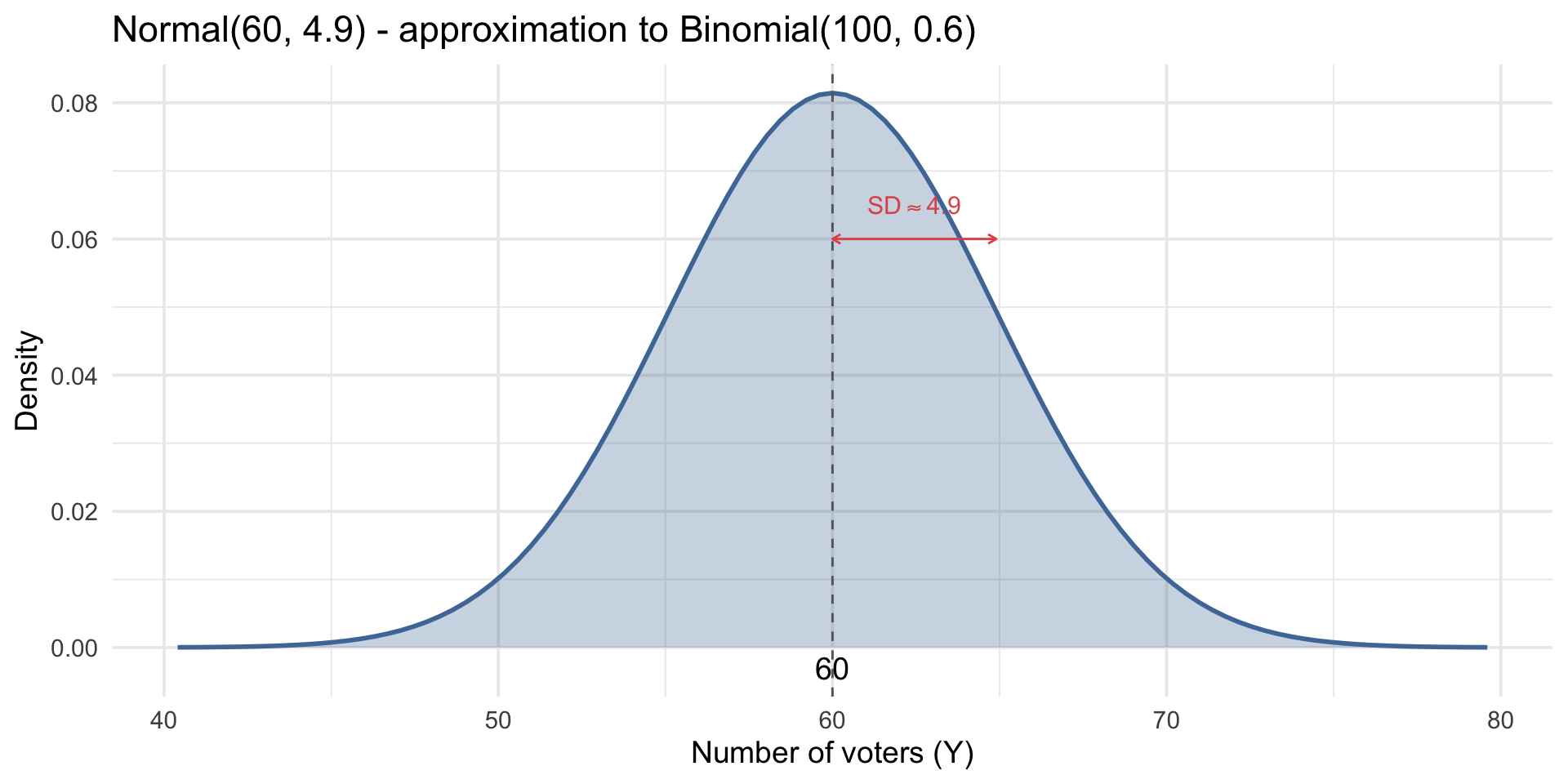
For continuous models, probabilities come from areas under the curve.
Key Properties of Normal Distributions
- Symmetric around the mean
- Mean, median, and mode coincide
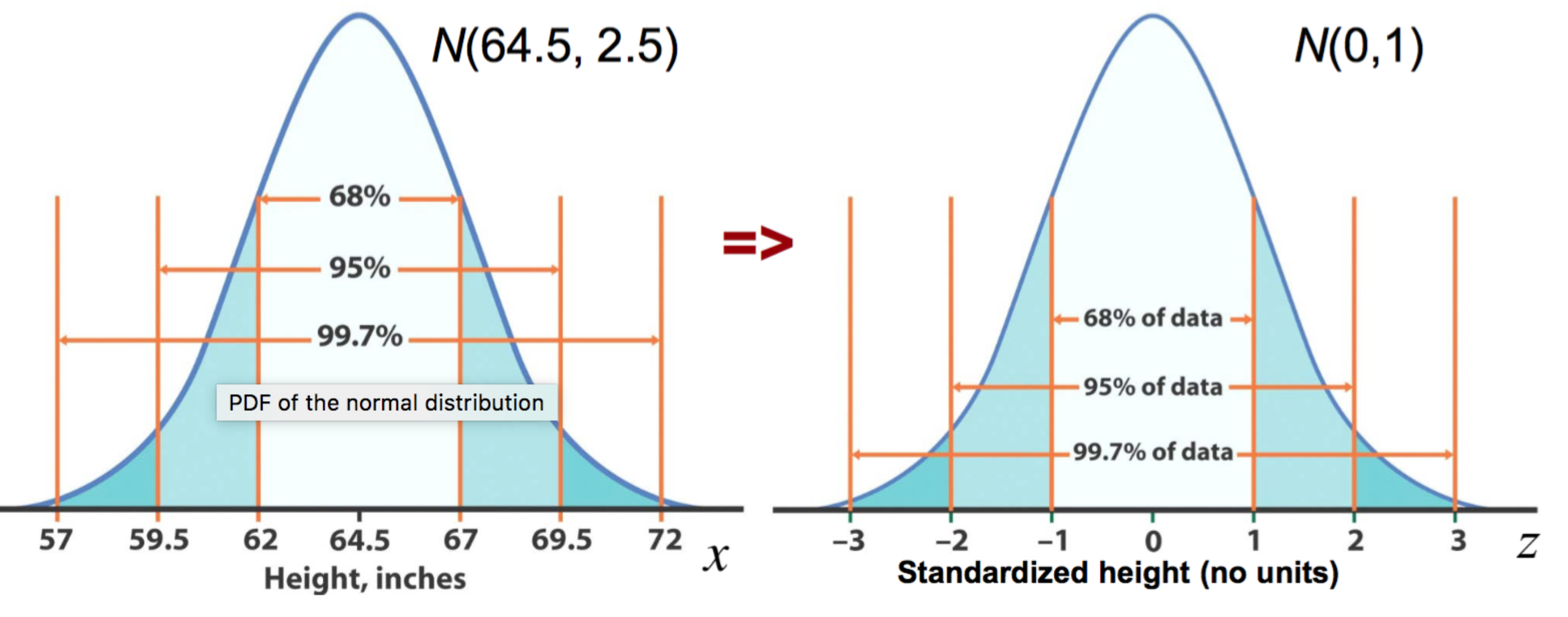
- 68-95-99.7 rule:
- within 1 SD (\(\pm 4.9\)): about 68% of samples → 55 to 65 voters
- within 2 SD (\(\pm 9.8\)): about 95% of samples → 50 to 70 voters
- within 3 SD (\(\pm 14.7\)): about 99.7% of samples → 45 to 75 voters
This rule gives us a quick way to judge whether an observed result is “typical” or “unusual.”
Standardization and Z-Scores
A z-score tells you how many standard deviations a value is from the mean:
\[z = \frac{\text{observed} - \text{mean}}{\text{SD}}\]
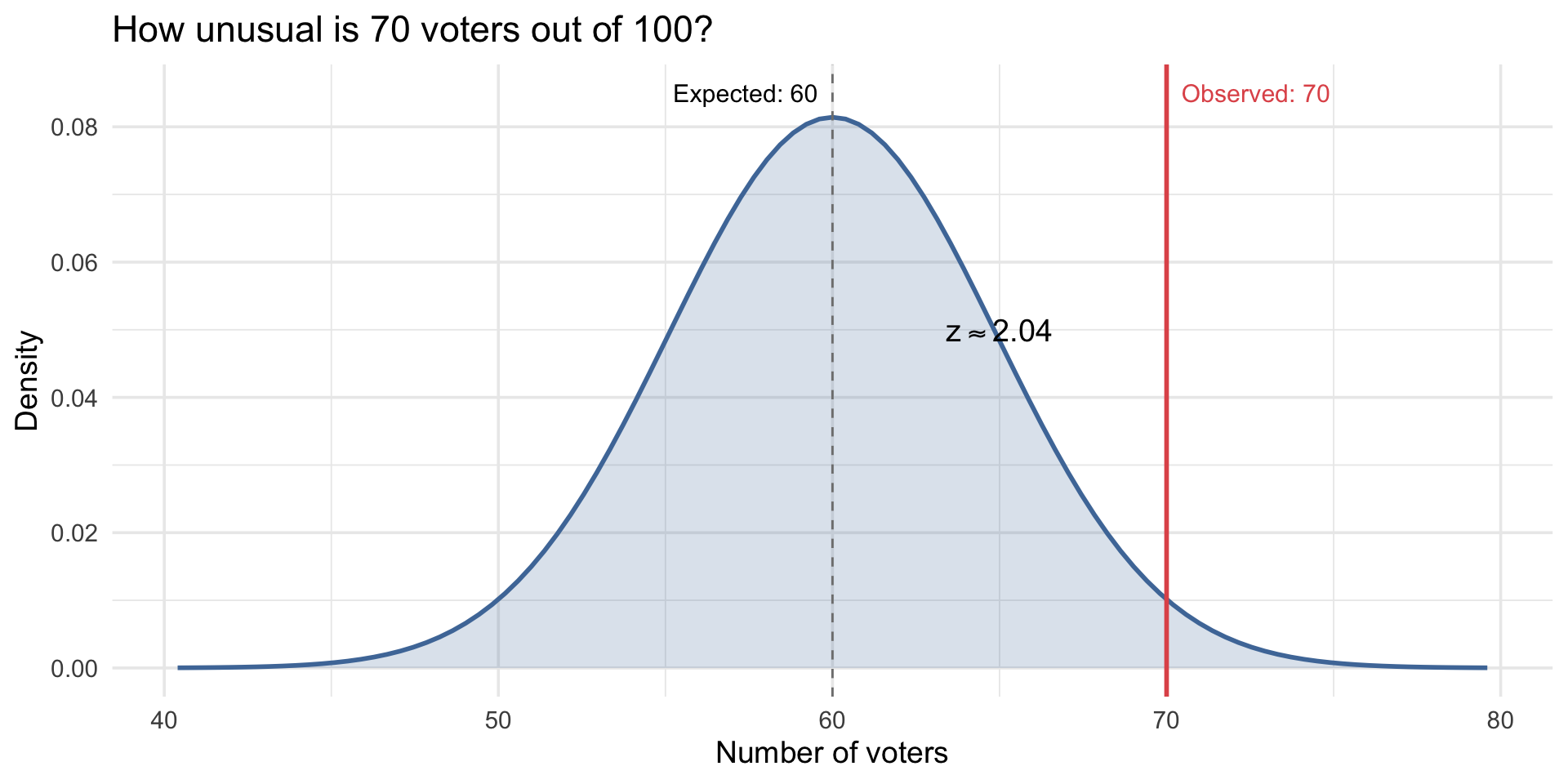
Example: We observed 70 voters out of 100. How unusual is that?
\[z = \frac{70 - 60}{4.9} \approx 2.04\]
That’s about 2 SDs above the mean. By the 68-95-99.7 rule, only about 2.5% of samples would show 70+ voters.
Computing Normal Probabilities in R
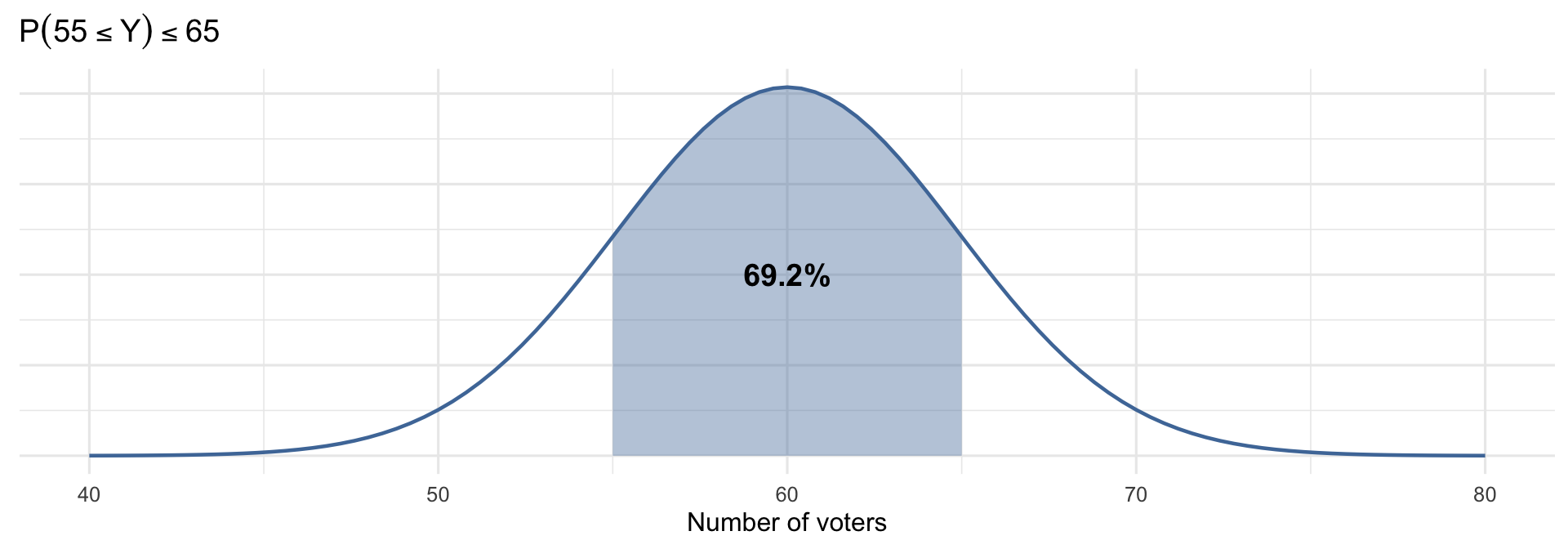
What’s the probability of observing between 55 and 65 voters?
What’s the probability of observing at most 50 voters?
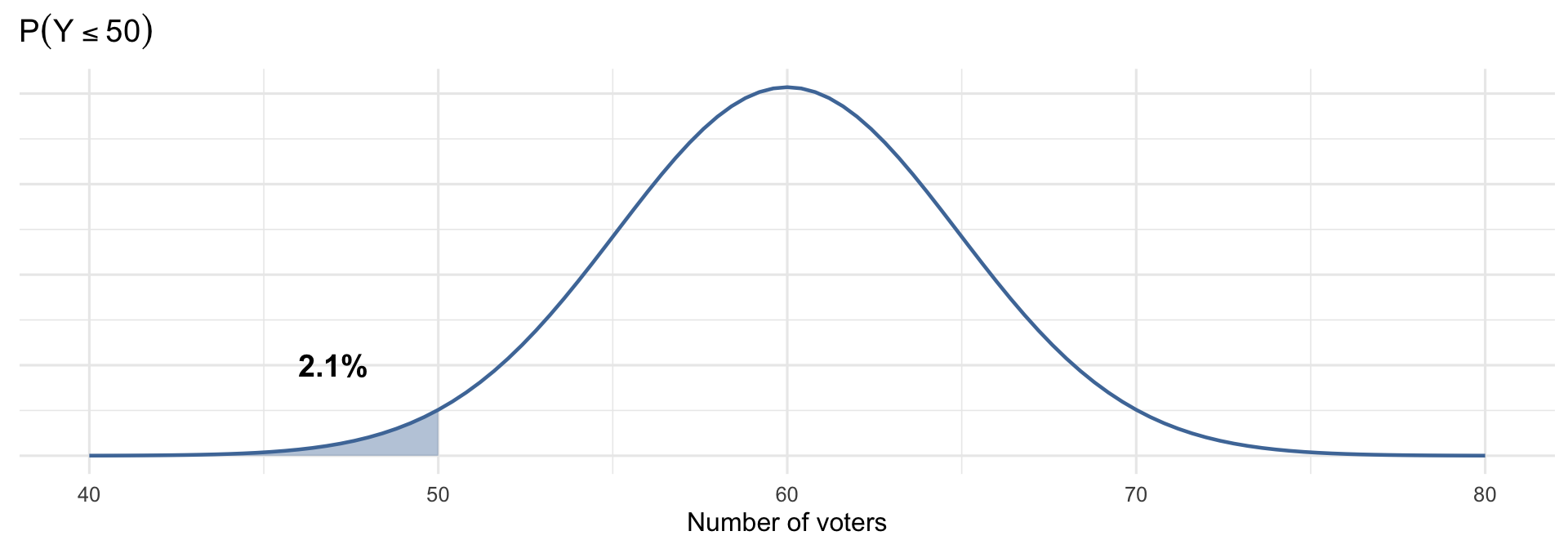
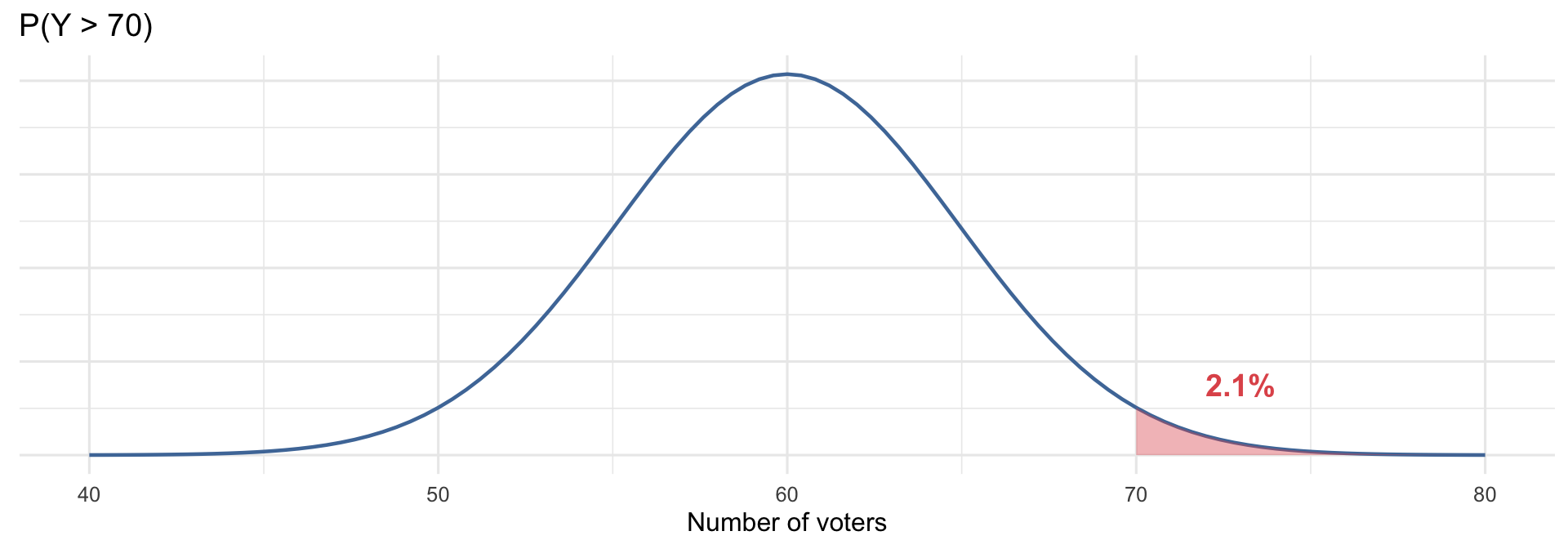
What’s the probability of observing more than 70 voters?
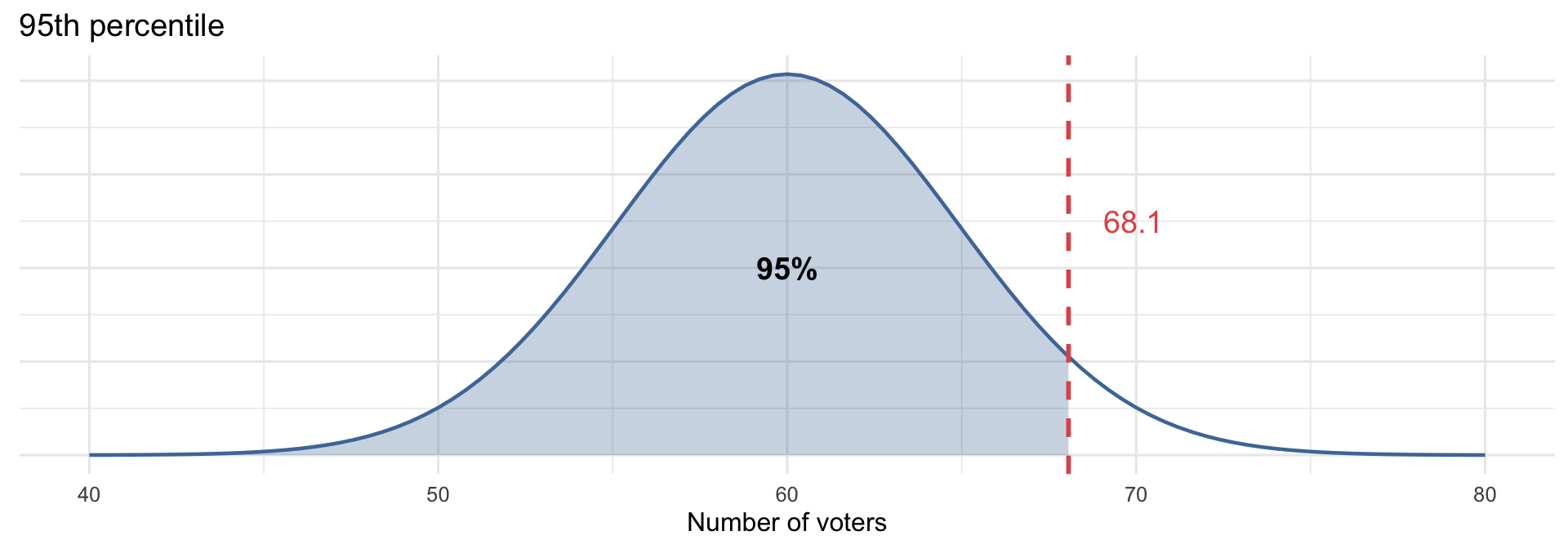
Practice: Z-Scores and Normal Probabilities
These examples are similar to what you’ll see on HW #5. Let’s work through them together.
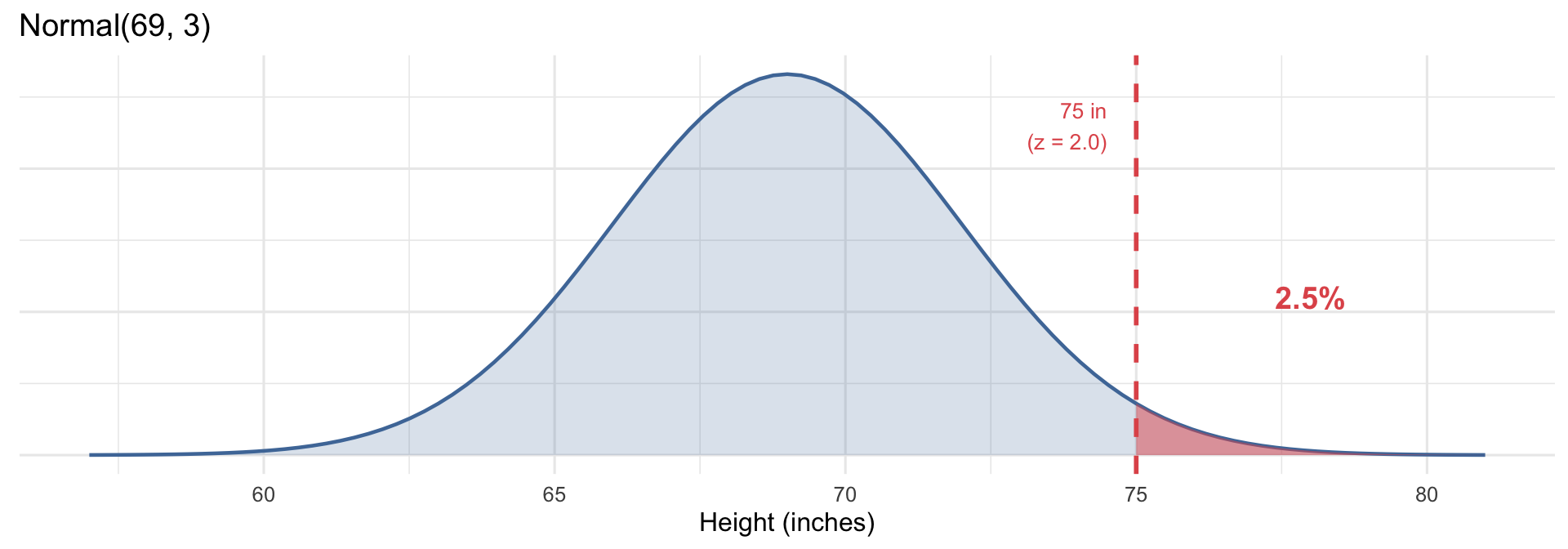
Andre’s height is 75 inches. Heights in his population are Normal with mean 69 inches and SD 3 inches. Calculate his z-score.
\[z = \frac{75 - 69}{3} = 2.0\]
Andre is 2 standard deviations above the mean. By the 68-95-99.7 rule, he is taller than about 97.5% of the population — only 2.5% of people are taller.
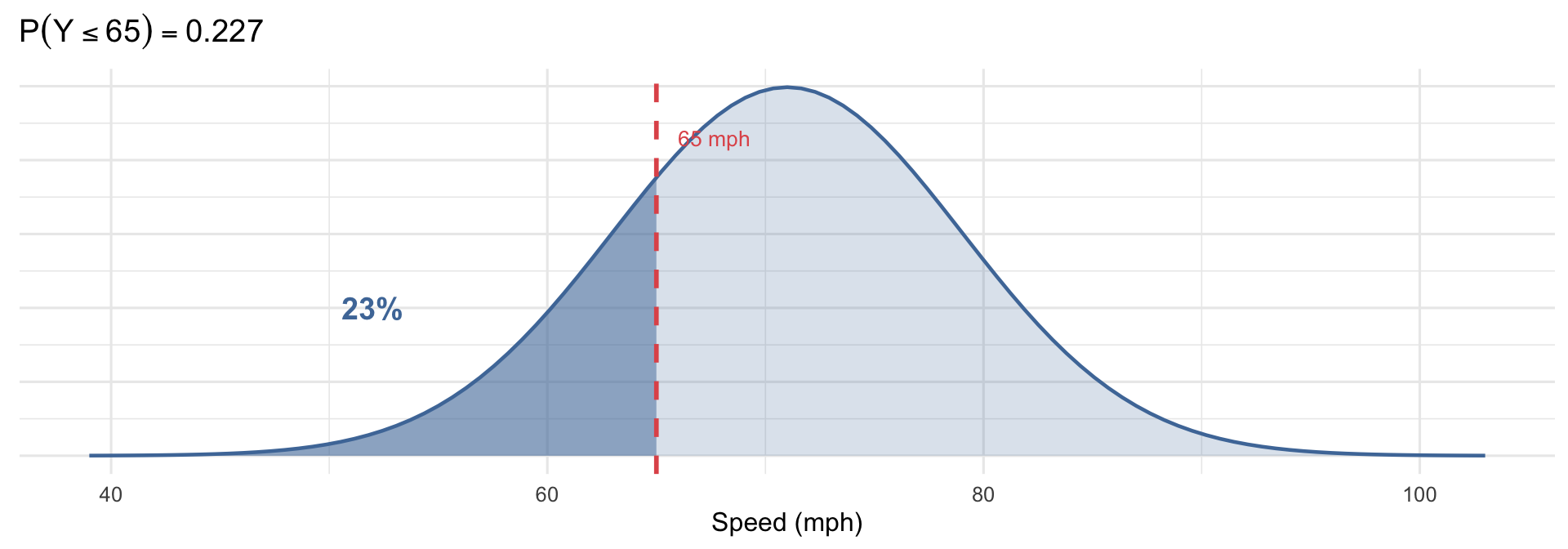
Vehicle speeds on I-5 are approximately Normal with mean 71 mph and SD 8 mph. The speed limit is 65 mph. What proportion of vehicles are at or below the speed limit?
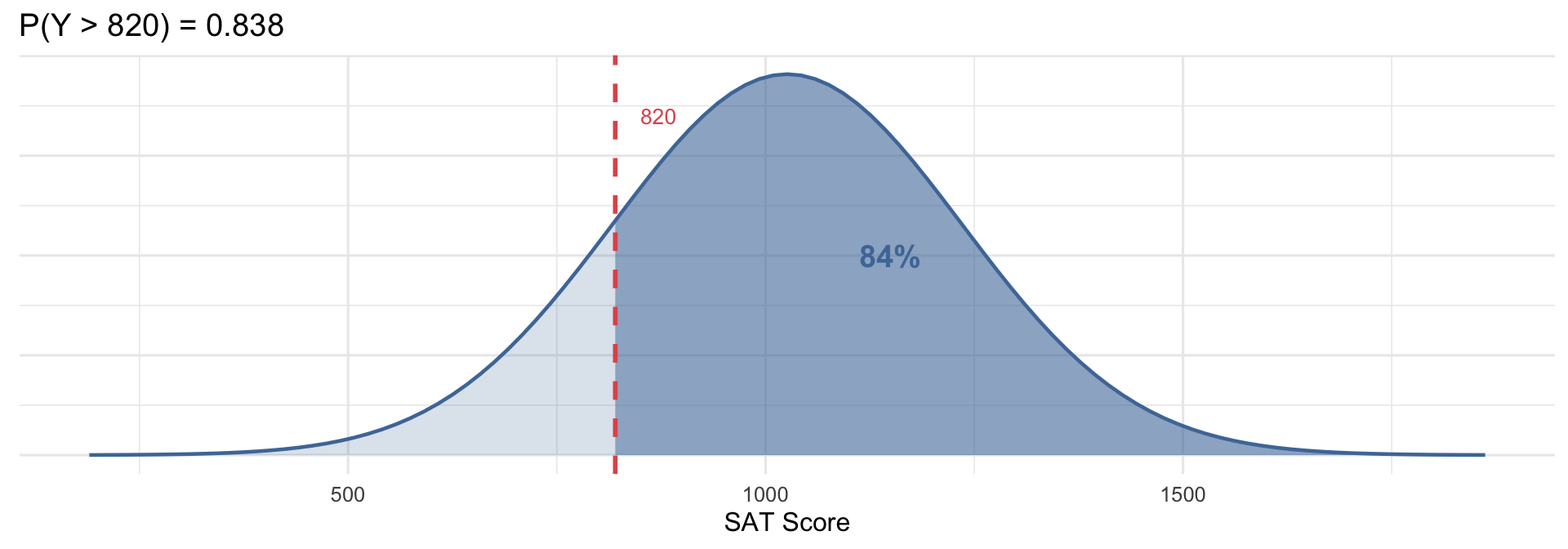
SAT scores are approximately Normal with mean 1026 and SD 209. The NCAA requires a score above 820 to compete. What proportion of students qualify?
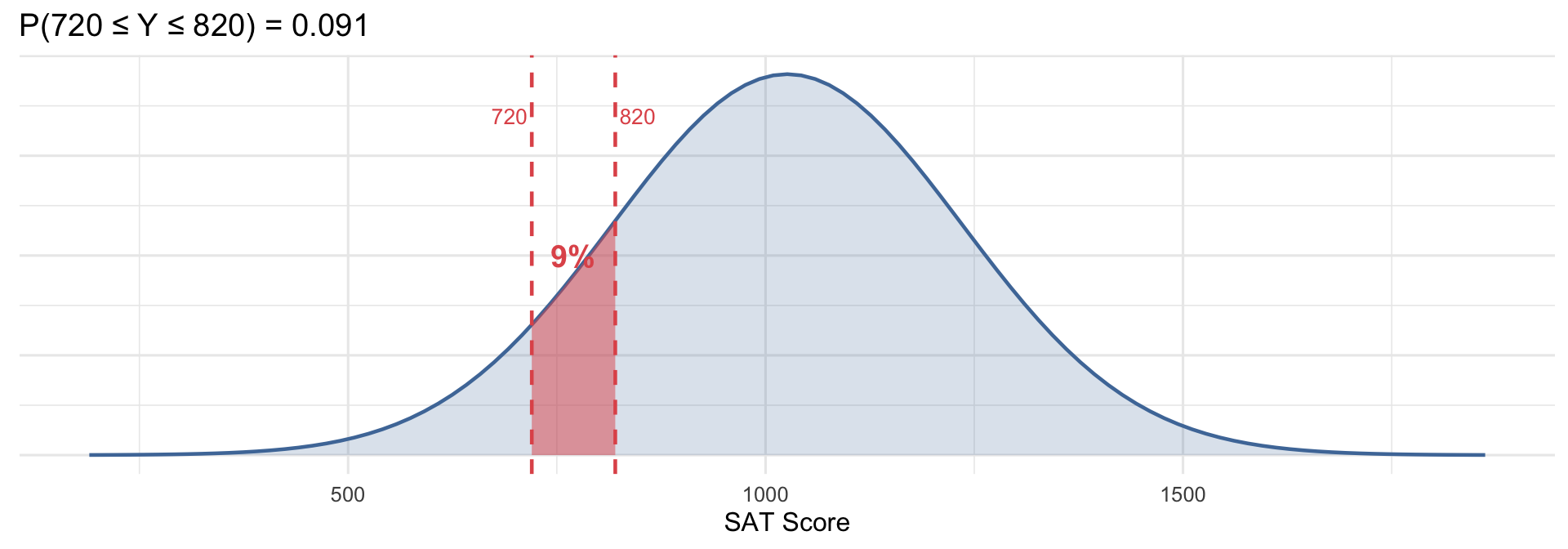
Using the same SAT distribution, what proportion score between 720 and 820 (partial qualifiers)?
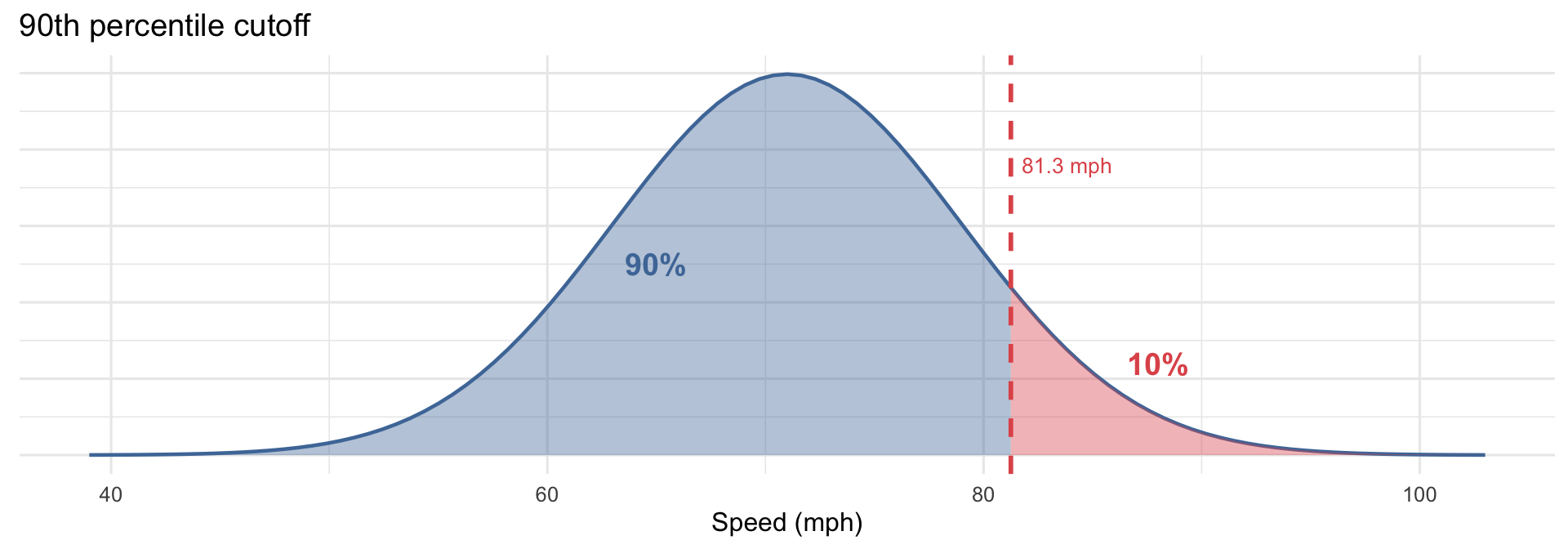
The Ladder, Visually
One trial → many trials → smooth approximation, all with \(\pi = 0.6\):
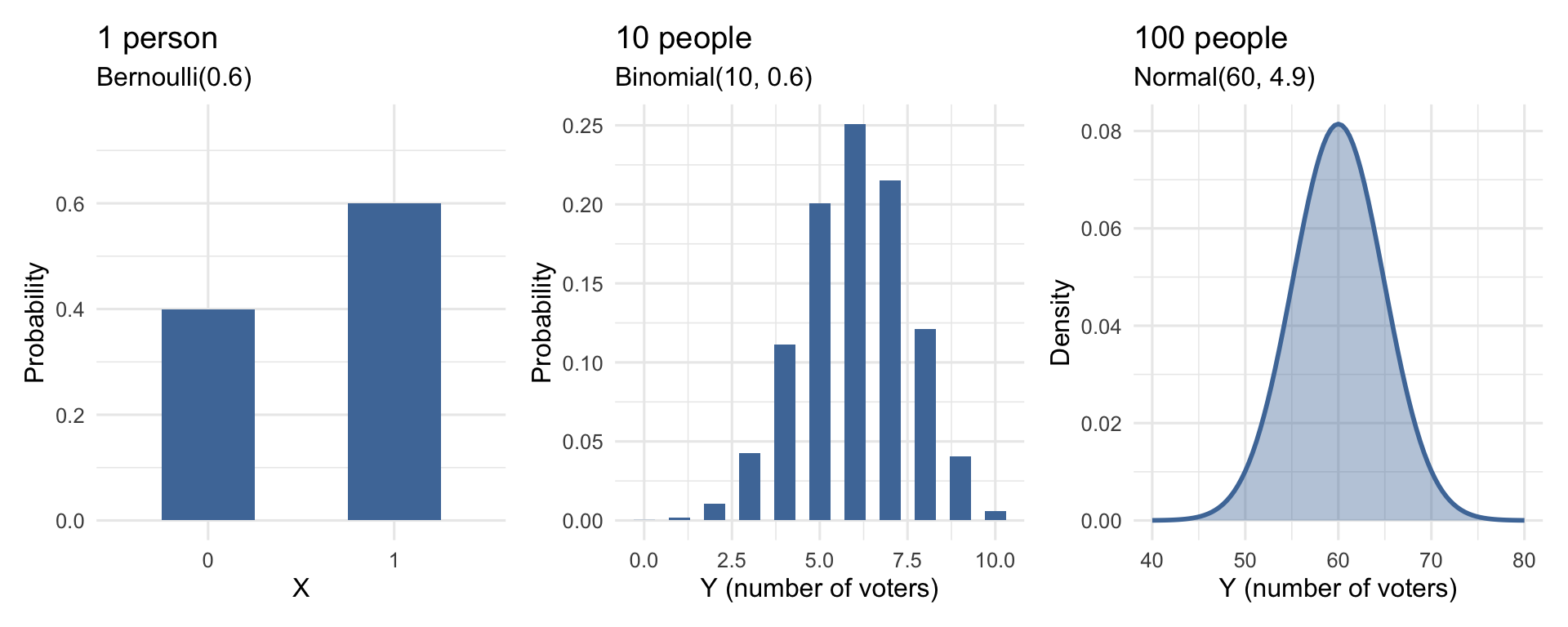
Same event, three levels of analysis. This is the logic that powers the rest of the course.