Week 5
Sociology 106: Quantitative Sociological Methods
February 17, 2026
Example: A Coin Toss
While the result of any single coin toss is random, the result over many tosses is predictable as long as the tosses are independent
If tosses are independent, then we can say that the probability of tossing “heads” is the proportion of “heads” in a large number of trials
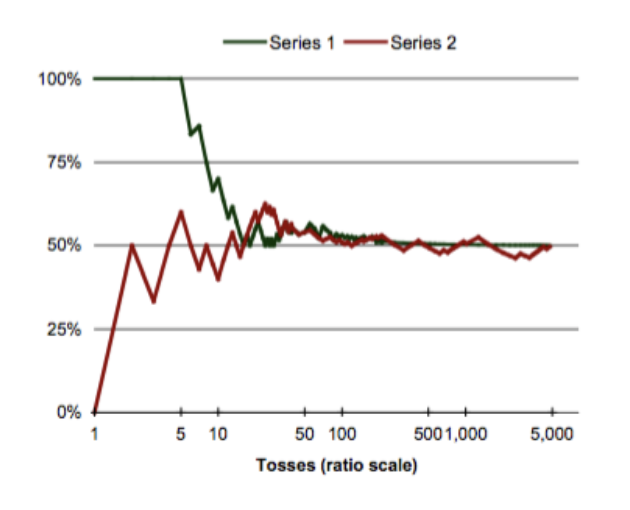
This illustrates how randomness at the individual level produces predictability at the aggregate level
Probabilities in Continuous Sample Spaces
We use density curves to represent probabilities across the continuous sample space, and compute probabilities for intervals as the area under the curve
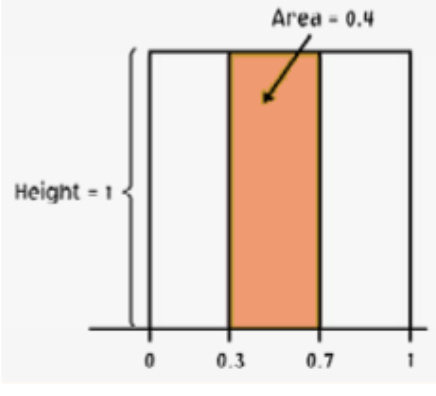
Example: Uniform density curve over \(S = [0,1]\) (all outcomes equally likely)
The shaded portion represents:
\(P(0.3 \leq x \leq 0.7) = (0.7 - 0.3) \times 1 = 0.4\)
Density Curves: Properties and Types
Properties:
- P(single point) = 0 — only intervals have non-zero probability
- Total area under the curve = 1
- Density curves are always non-negative
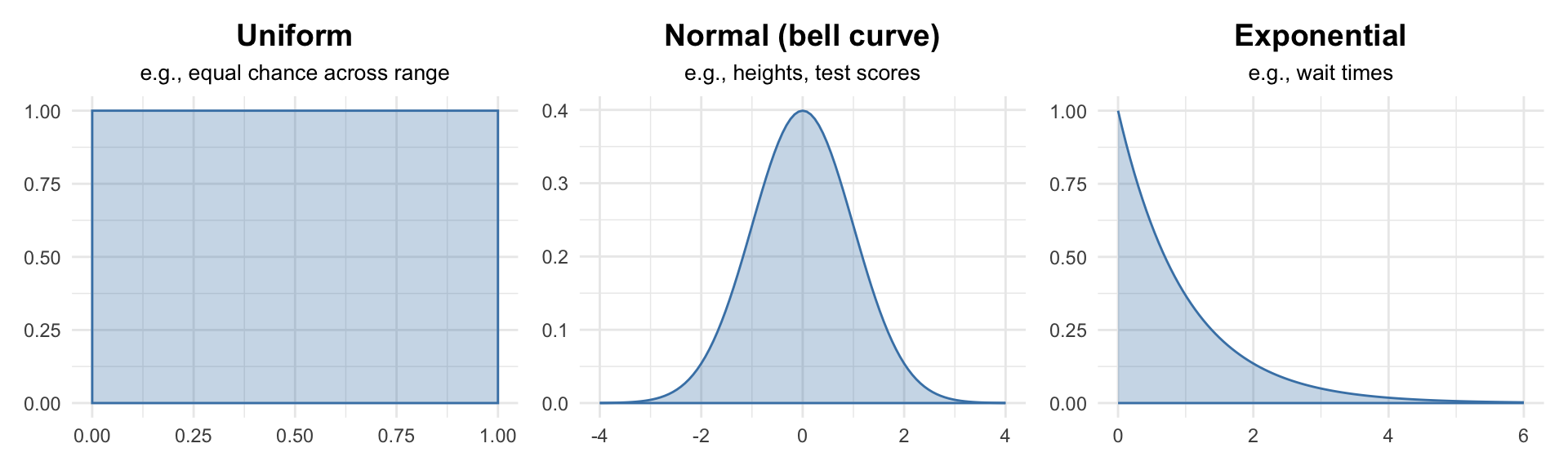
Common types we’ll encounter (we’ll use these extensively when we study the normal distribution):
Addition Rule: Union of “A or B”
The union of A and B (“A or B”) consists of outcomes that are in A, or in B, or in both A and B. Notation: \(A \cup B\)
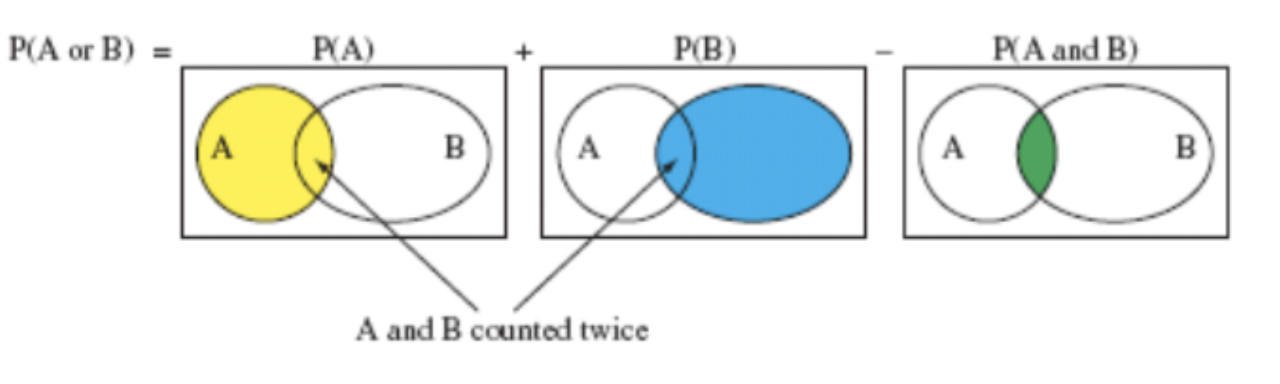
For the union of two events,
\[P(A \text{ or } B) = P(A) + P(B) - P(A \text{ and } B)\]
We subtract \(P(A \text{ and } B)\) to avoid double-counting outcomes in both events
Notice: even in an “or” problem, we still need the overlap term \(P(A \text{ and } B)\)
If the events are disjoint (mutually exclusive), then \(P(A \text{ and } B) = 0\)
\[P(A \text{ or } B) = P(A) + P(B)\]
Disjoint events have no overlap, so there’s nothing to subtract
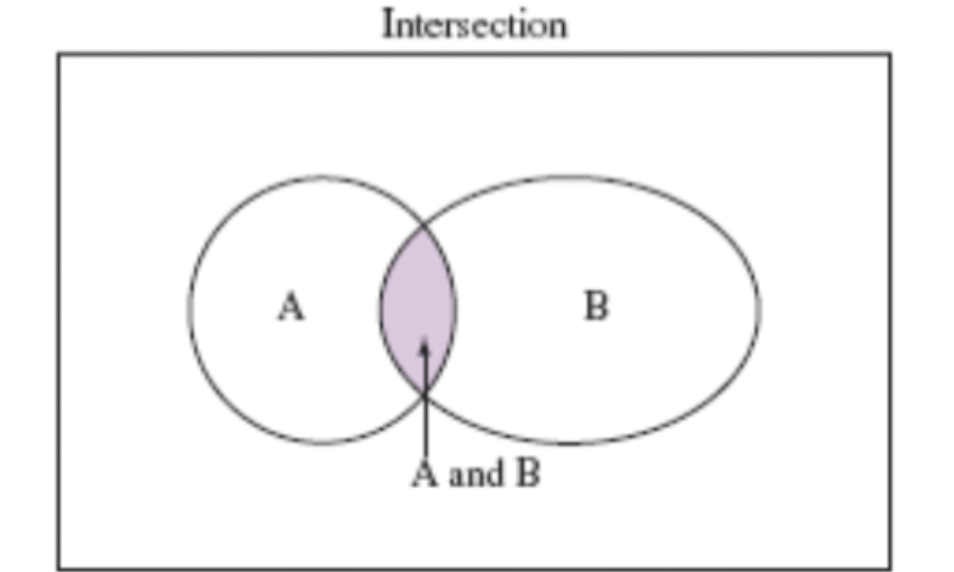
Intersection and Conditional Probabilities
The intersection of A and B (\(A \cap B\)) consists of outcomes that are in both A and B — the overlap between two events
The conditional probability of event A, given that event B has occurred, is:
\[P(A|B) = \frac{P(A \text{ and } B)}{P(B)}\]
- \(P(A|B)\) is read as “the probability of A, given B”