Week 14
Sociology 106: Quantitative Sociological Methods
April 21, 2026
The Three-Effect Framework
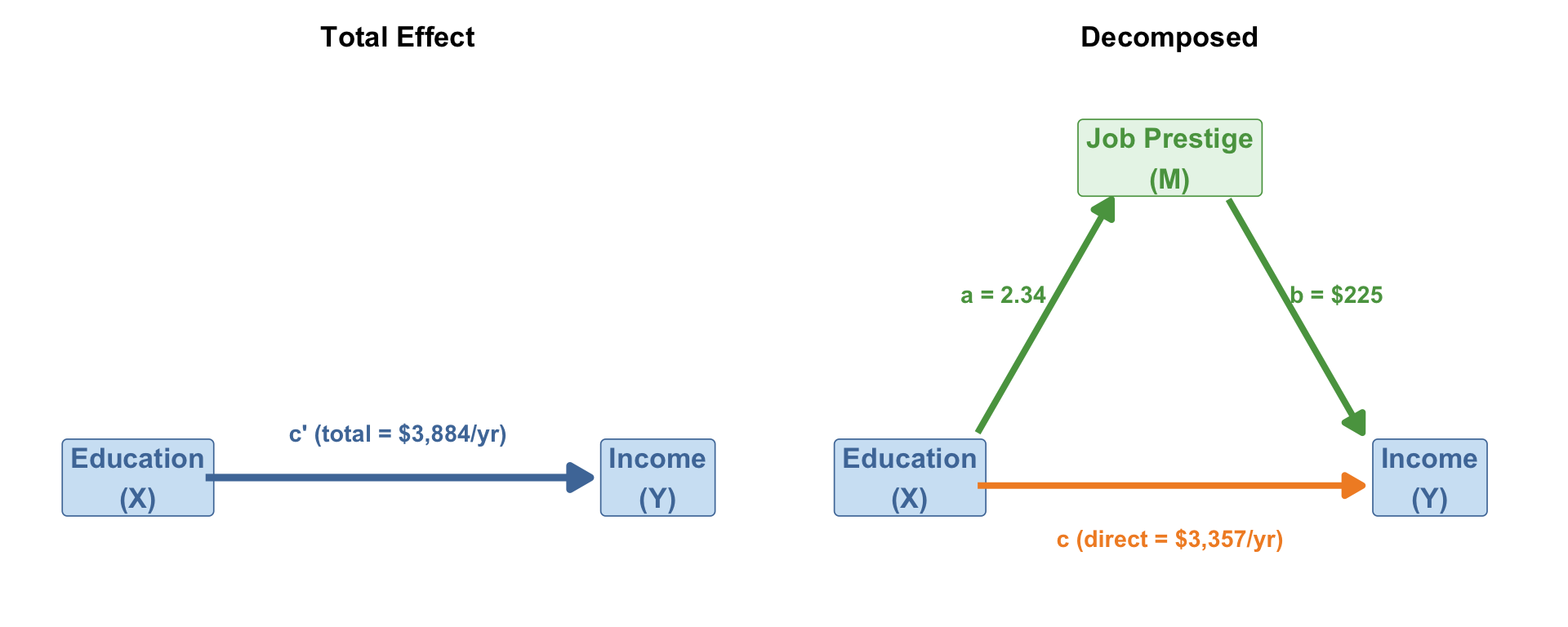
\[\underbrace{c'}_{\text{total}} = \underbrace{c}_{\text{direct}} + \underbrace{a \times b}_{\text{indirect}}\]
- Total effect (c’): the overall X → Y relationship (before adding M)
- Direct effect (c): X → Y after controlling for M
- Indirect effect (a × b): the part of X’s effect that travels through M
Full vs. Partial Mediation
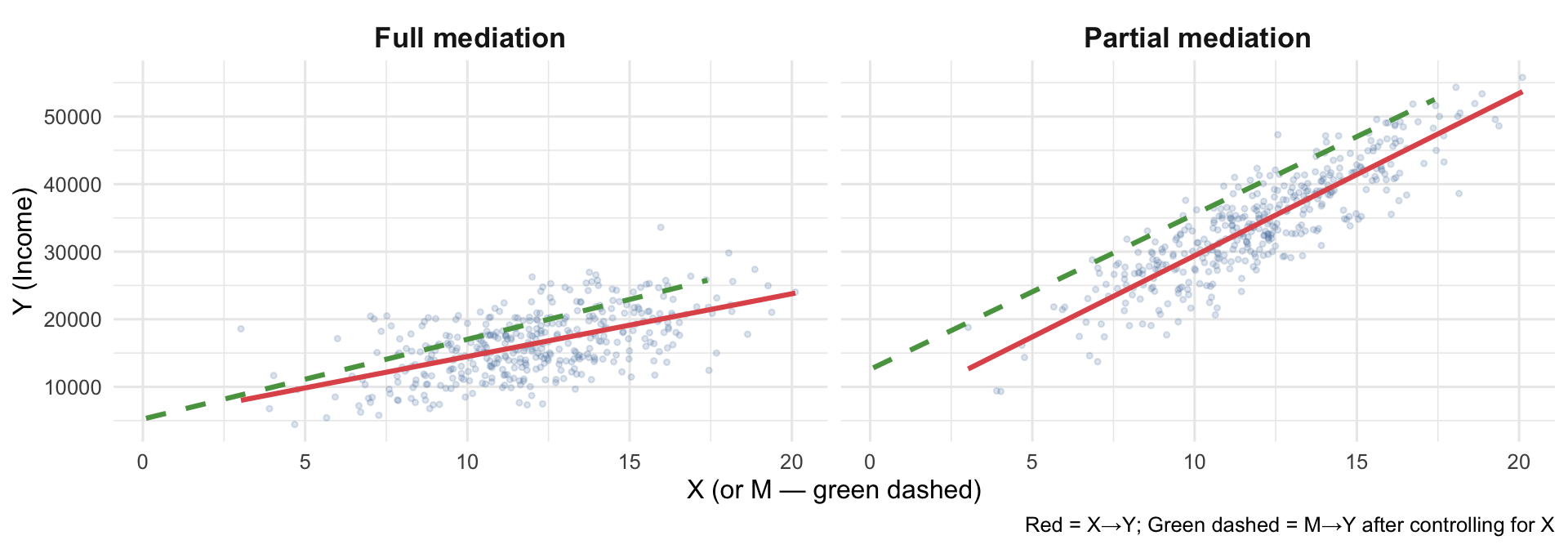
Full mediation
The direct effect c drops to (near) zero when M enters the model.
M fully explains why X affects Y.
The indirect path is the whole story.
Partial mediation
The direct effect c decreases but remains significant.
M explains part of the mechanism; something else also connects X directly to Y.
Both paths matter.
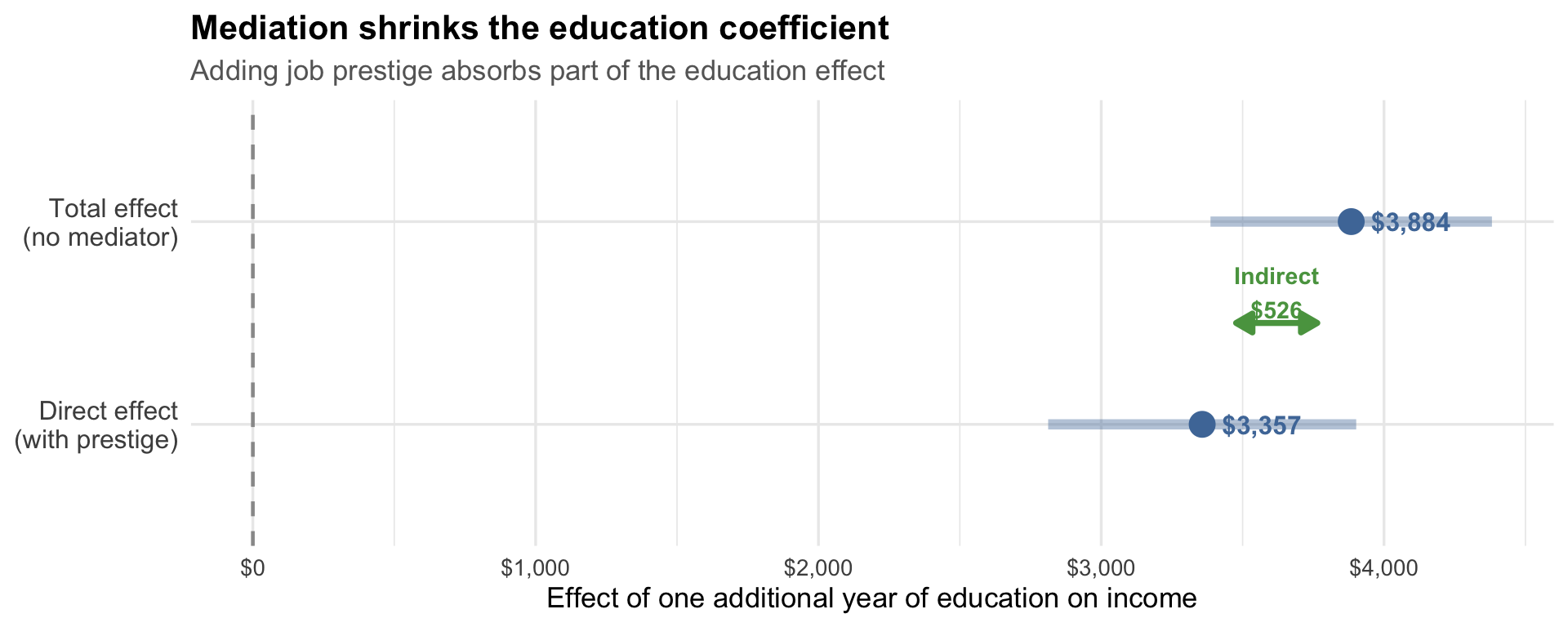
Visualizing the Indirect Effect
What Is Multicollinearity?
Multicollinearity occurs when two or more predictors in a regression are highly correlated with each other.
Why it’s a problem:
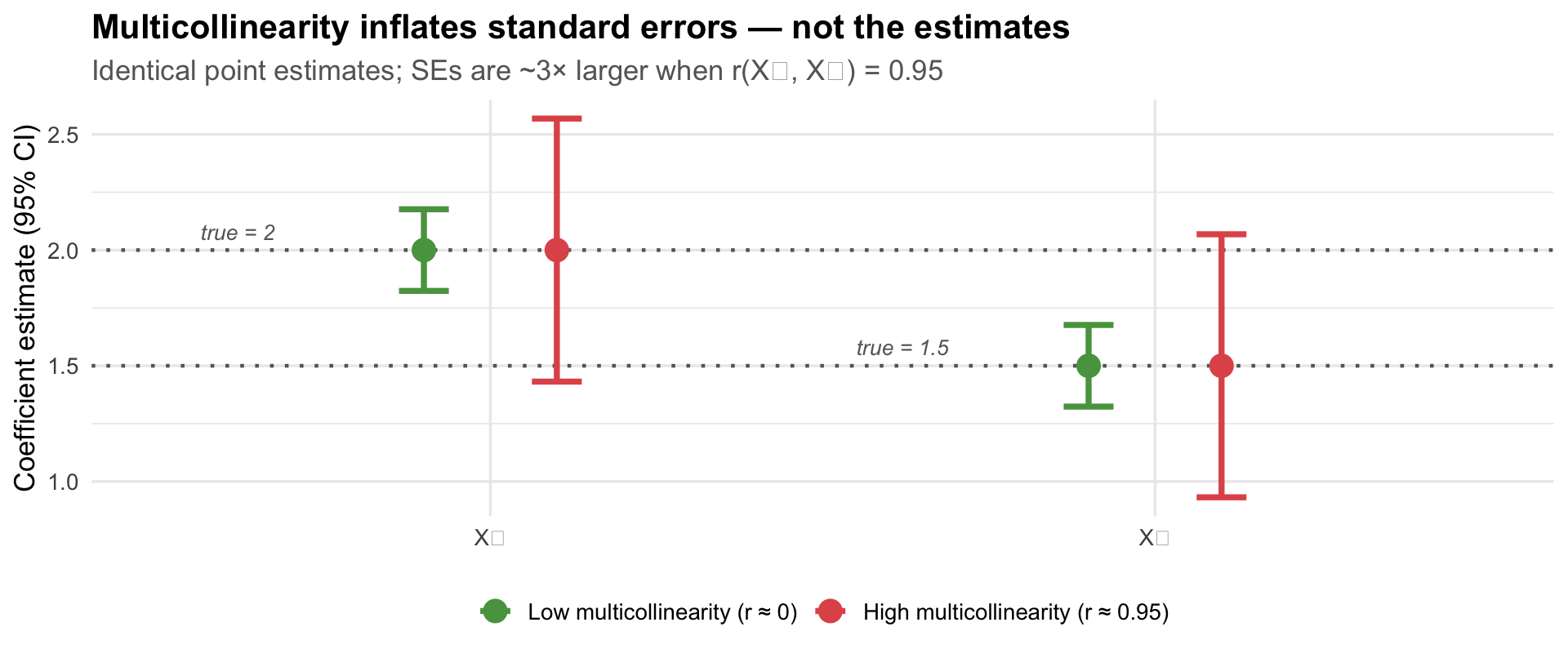
When X₁ and X₂ are highly correlated: - The model can’t tell which one is doing the work - Coefficient estimates become unstable — tiny data changes → large coefficient changes - Standard errors inflate → wide confidence intervals → everything looks non-significant - Coefficients can flip sign or become implausibly large
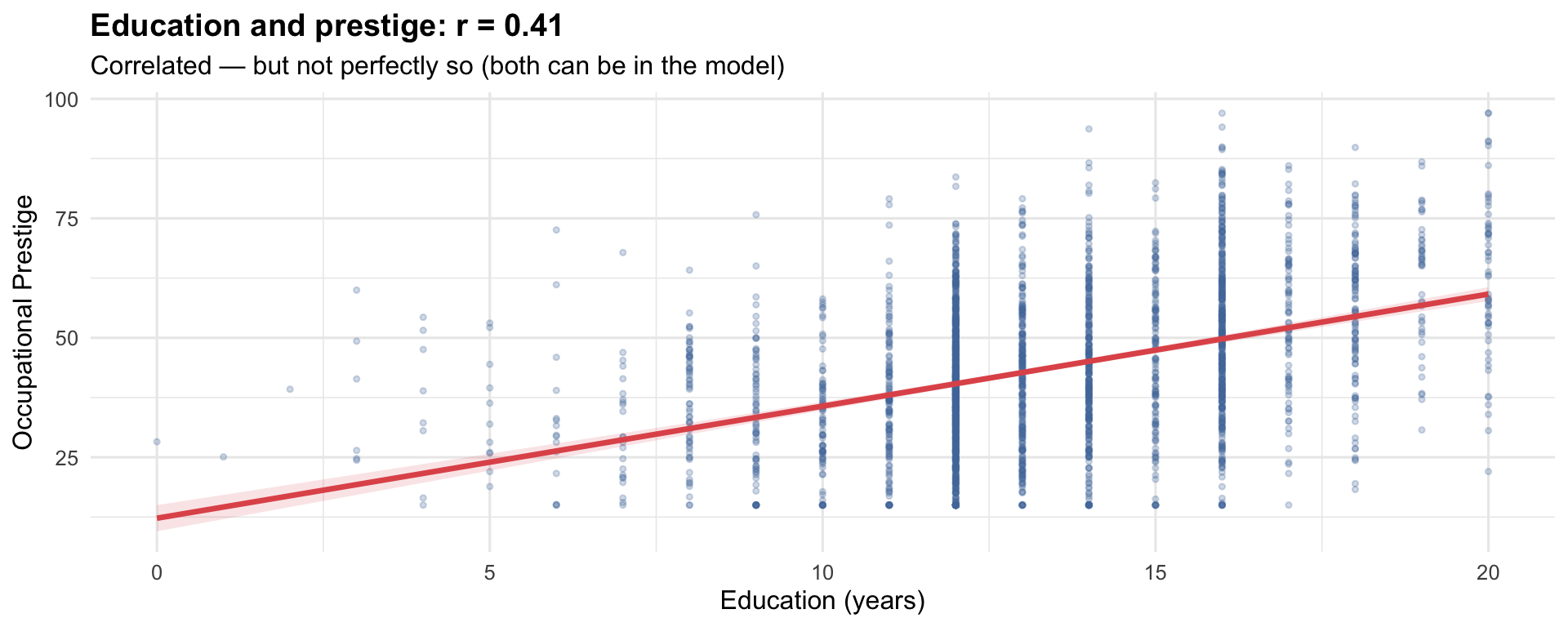
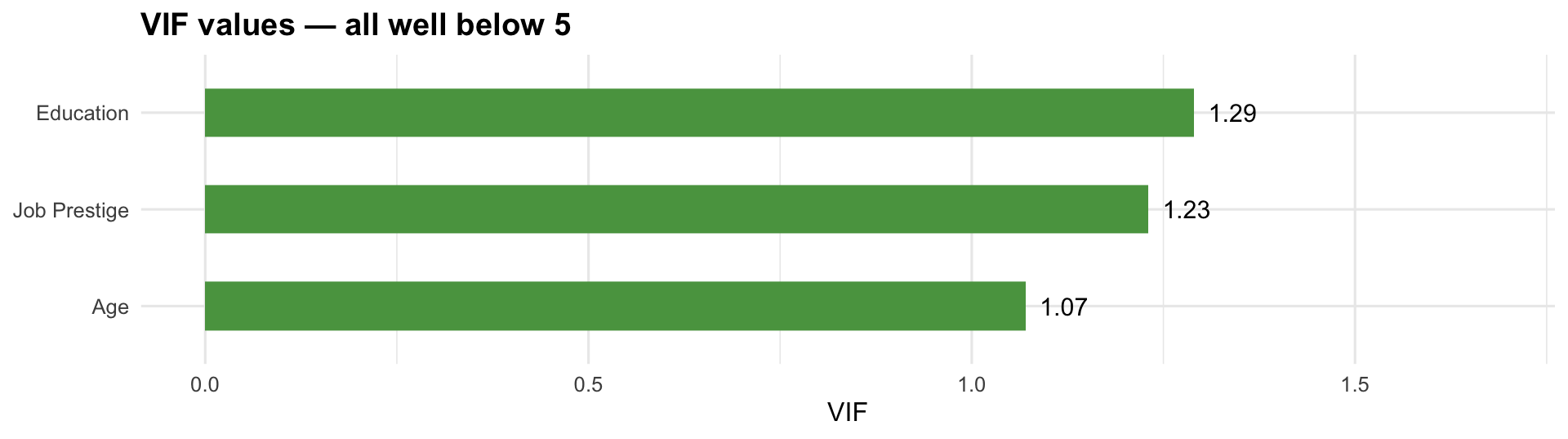
Detecting Multicollinearity: VIF
The Variance Inflation Factor (VIF) measures how much each predictor’s variance is inflated by correlation with the others.
\[\text{VIF}_j = \frac{1}{1 - R^2_j}\]
where \(R^2_j\) is the R² from regressing predictor \(j\) on all other predictors.
Rules of thumb:
| VIF | Interpretation |
|---|---|
| 1 | No multicollinearity |
| 1–5 | Low — acceptable |
| 5–10 | Moderate — investigate |
| > 10 | Severe — take action |
What Multicollinearity Looks Like
What Your Final Paper Needs
Required components:
| Component | What to include |
|---|---|
| Bivariate model | lm(Y ~ X) — your key IV predicting Y |
| Multivariate model | Add at least 2 controls; discuss why they matter |
| Extension | At least one of: interaction, mediation, or logistic (if binary Y) |
| Assumption check | Residual plot + VIF — a paragraph is sufficient |
| Model table | modelsummary() comparing models side-by-side |
Don’t just report the number — tell the story:
| Instead of… | Try… |
|---|---|
| “The coefficient on education is 1847.” | “Each additional year of education is associated with $1,847 higher income, holding sex and age constant.” |
| “The interaction term is significant.” | “The education–income association is steeper for men than women: each year of education yields approximately $[gap] more income for men.” |
| “ACME = 624, p < 0.05.” | “About [%]% of education’s effect on income appears to operate through occupational prestige.” |
Every quantitative paper needs a limitations section. Be specific, not generic.
Generic (avoid): > “This study has some limitations. The data may not be perfectly representative.”
Specific (better): > “Because the GSS uses cross-sectional data, we cannot establish the temporal ordering required for causal inference. Specifically, the mediation claim — that education affects income through occupational prestige — requires that education precede prestige, which we assume but cannot verify. Additionally, unmeasured confounders of the prestige–income relationship (e.g., parental occupational networks) may bias the indirect effect estimate.”
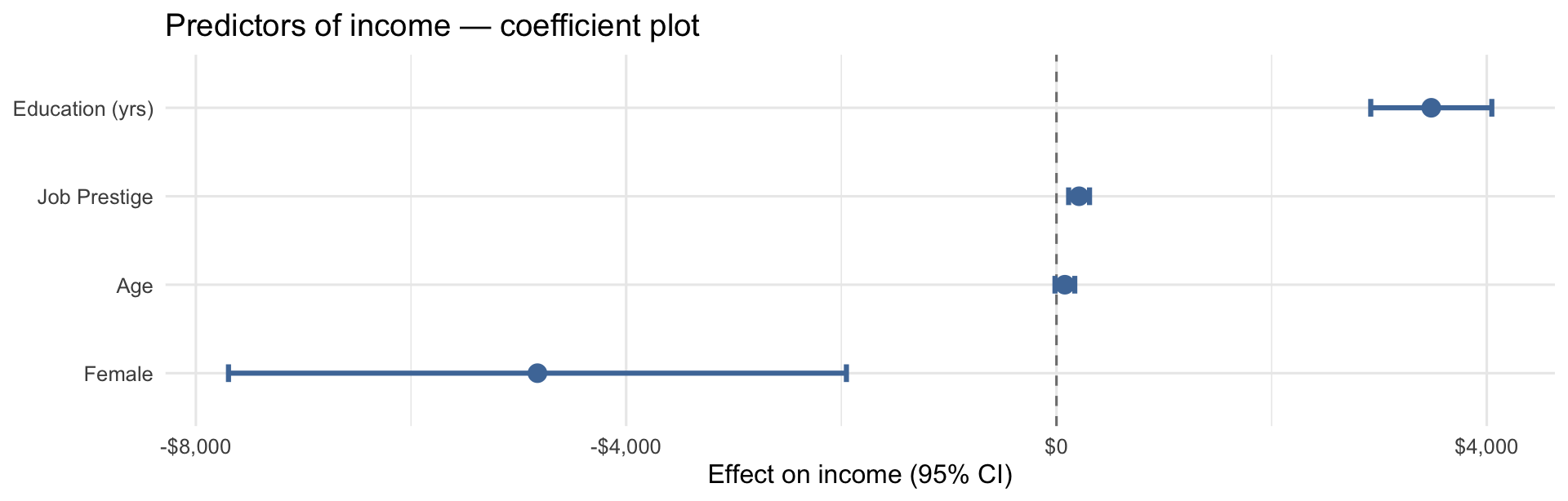
A coefficient plot shows each predictor’s estimated effect and its confidence interval as a dot-and-whisker. It lets readers immediately see which effects are large, which are small, and which cross zero (non-significant).
Use a coefficient plot in your presentation instead of the full regression table — tables are hard to read aloud. Use the table in your paper.
library(broom)
model_coefplot <- lm(income91 ~ educ + prestg80 + sex_f + age,
data = attain_med)
tidy(model_coefplot, conf.int = TRUE) |>
filter(term != "(Intercept)") |>
mutate(term = case_match(term,
"educ" ~ "Education (yrs)",
"prestg80" ~ "Job Prestige",
"sex_ffemale" ~ "Female",
"age" ~ "Age"
)) |>
ggplot(aes(x = estimate, y = fct_reorder(term, estimate))) +
geom_vline(xintercept = 0, linetype = "dashed", color = "gray50") +
geom_errorbarh(aes(xmin = conf.low, xmax = conf.high),
height = 0.2, linewidth = 1.1, color = "#4E79A7") +
geom_point(size = 3.5, color = "#4E79A7") +
scale_x_continuous(labels = scales::dollar_format()) +
labs(x = "Effect on income (95% CI)", y = NULL,
title = "Predictors of income — coefficient plot") +
theme_minimal(base_size = 12)