Week 13
Sociology 106: Quantitative Sociological Methods
April 14, 2026
A Classic Example: Computers and Test Scores
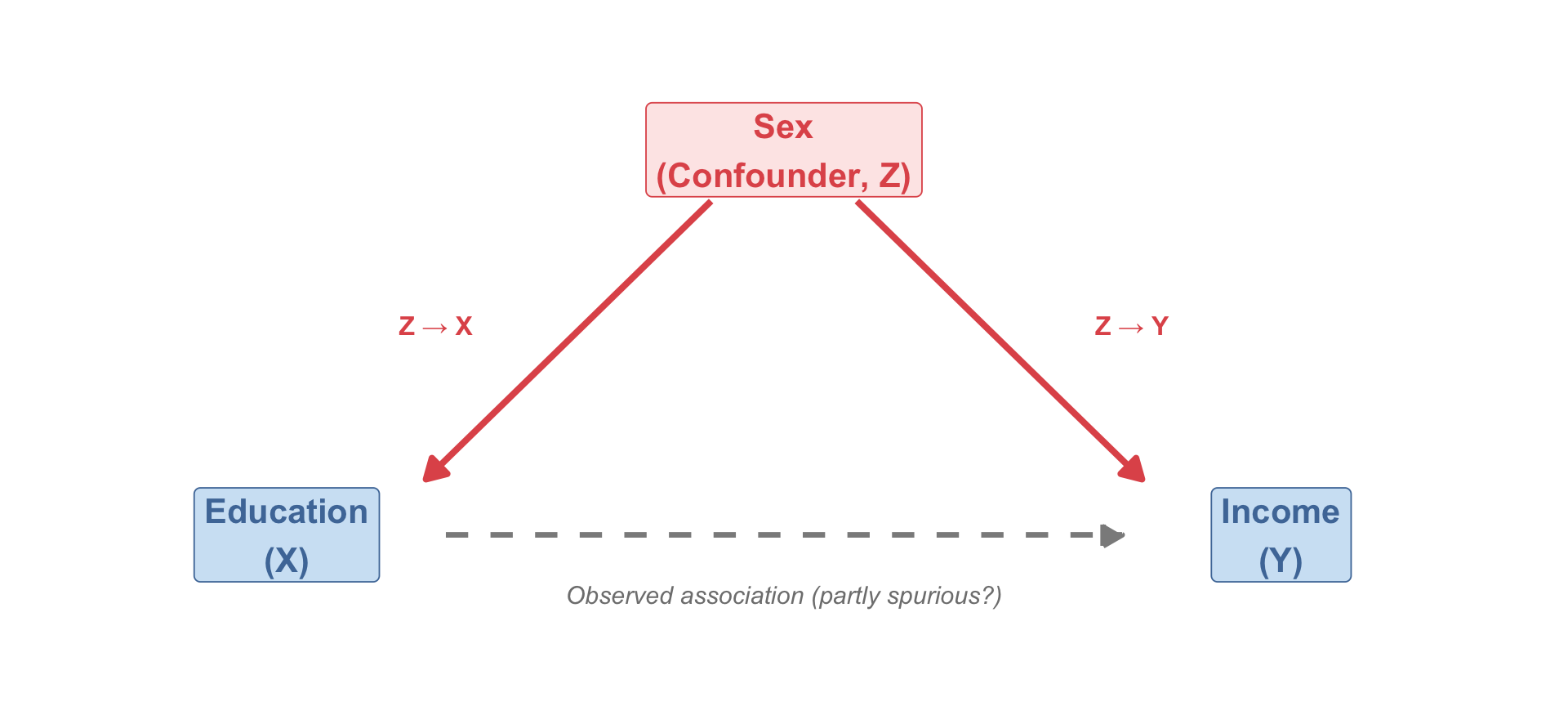
In the early 1990s, researchers found: households with home computers had children with higher math test scores.
Does computer ownership cause better academic performance?
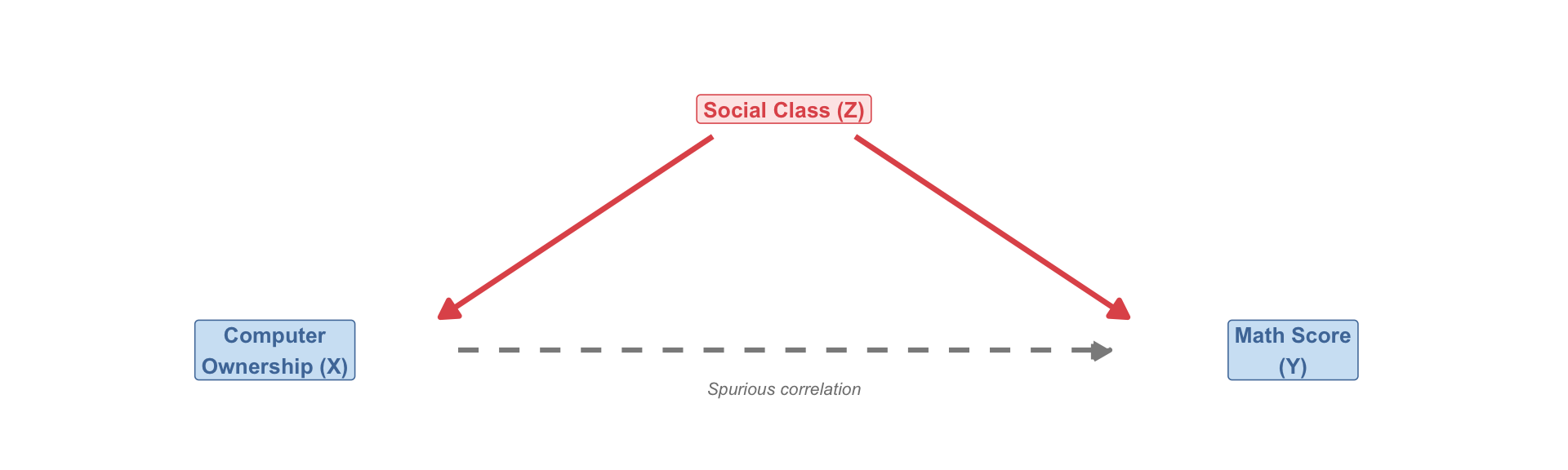
Social class caused both computer ownership and math achievement — it was the confound:
- Higher-class families could afford computers (Z → X)
- Higher-class families also provided better academic resources (Z → Y)
When researchers controlled for social class — comparing families at the same class level — the computer–test score correlation vanished.
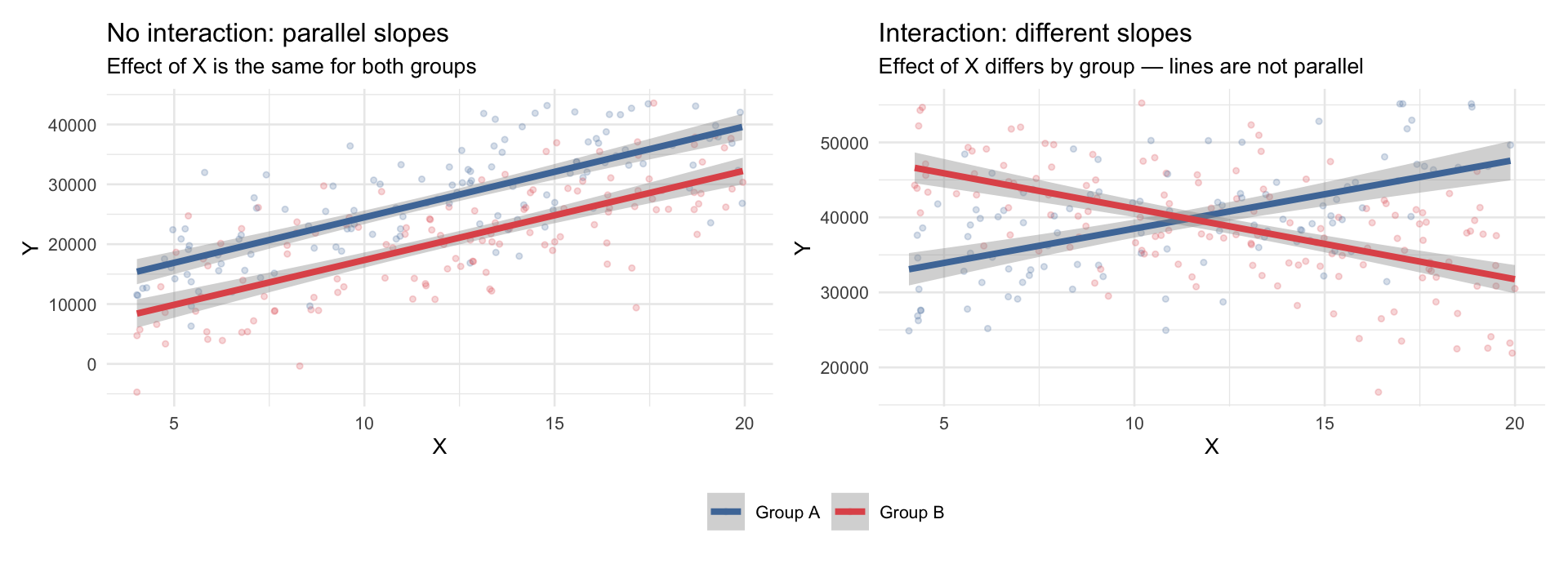
Parallel vs. Non-Parallel Slopes
The key visual difference between a model without an interaction and one with an interaction:
Visualizing Interaction Terms
Model: lm(income91 ~ prestg80 * age) — does the income payoff of occupational prestige depend on career stage?
People often visualize the dependency of one variable on the other by breaking the variable of interest into different groups. Here, age is broken into three relevant analytical groups; if there are no clear breaks, use standard deviations.
Code
p_int <- ggpredict(model_prestige, terms = c("prestg80", "age [30, 45, 60]")) |>
ggplot(aes(x = x, y = predicted, color = group, fill = group)) +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = 0.15, color = NA) +
geom_line(linewidth = 1.4) +
scale_color_manual(
values = c("#E15759", "#4E79A7", "#59A14F"),
labels = c("Age 30", "Age 45", "Age 60"),
name = "Age"
) +
scale_fill_manual(
values = c("#E15759", "#4E79A7", "#59A14F"),
labels = c("Age 30", "Age 45", "Age 60"),
name = "Age"
) +
scale_y_continuous(labels = scales::dollar_format(big.mark = ",")) +
labs(
title = "With interaction",
subtitle = "Slope varies by age — does prestige compound over a career?",
x = "Occupational Prestige Score",
y = "Predicted Income ($)"
) +
theme_minimal(base_size = 10) +
theme(legend.position = "bottom")
p_int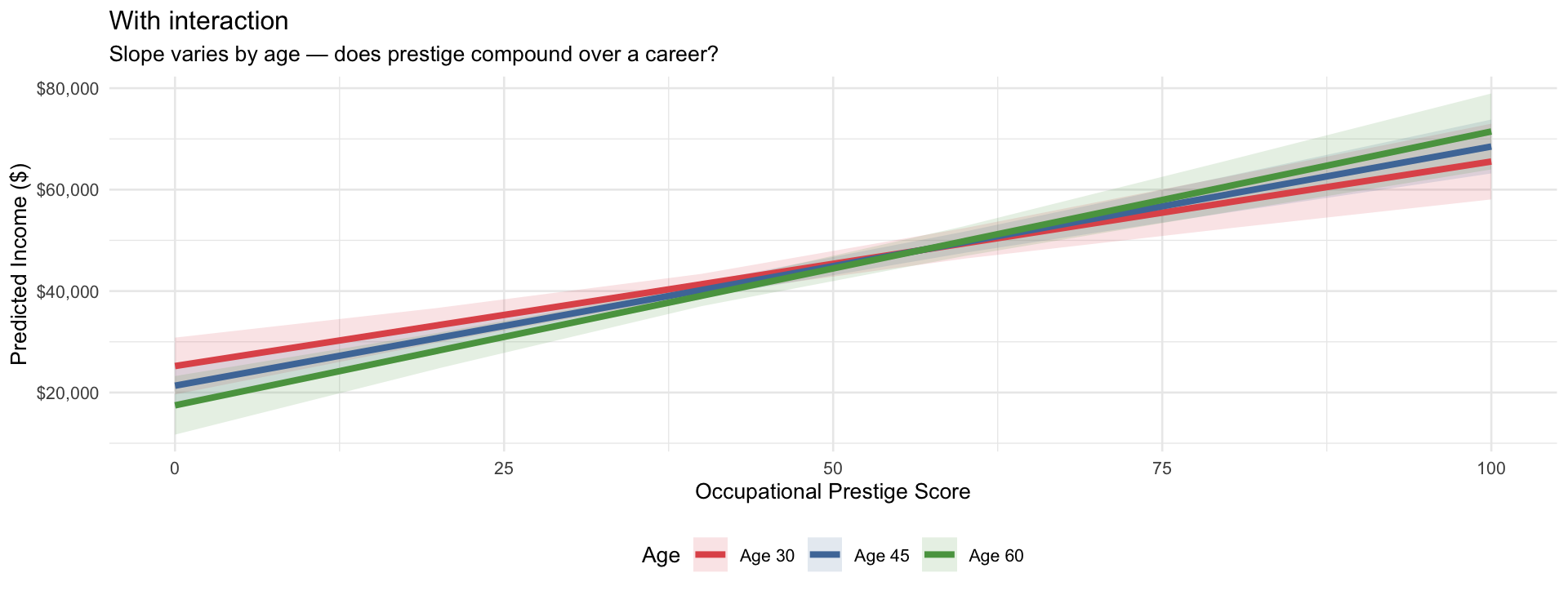
Model: lm(income91 ~ educ * sex_f) — does the income return to education differ by sex?
This is simpler to visualize since the categories are already decided for you, unlike with a continuous by continuous interaction.
Code
ggpredict(model_interact, terms = c("educ [4:20 by=0.5]", "sex_f")) |>
ggplot(aes(x = x, y = predicted, color = group, fill = group)) +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = 0.15, color = NA) +
geom_line(linewidth = 1.4) +
scale_color_manual(
values = c("male" = "#4E79A7", "female" = "#E15759"),
labels = c("Men", "Women"), name = "Sex"
) +
scale_fill_manual(
values = c("male" = "#4E79A7", "female" = "#E15759"),
labels = c("Men", "Women"), name = "Sex"
) +
scale_y_continuous(labels = scales::dollar_format(big.mark = ",")) +
labs(
title = "Predicted Income by Education and Sex",
subtitle = "lm(income91 ~ educ * sex_f) — interaction non-significant",
x = "Years of Education",
y = "Predicted Income ($)"
) +
theme_minimal(base_size = 11) +
theme(legend.position = "bottom")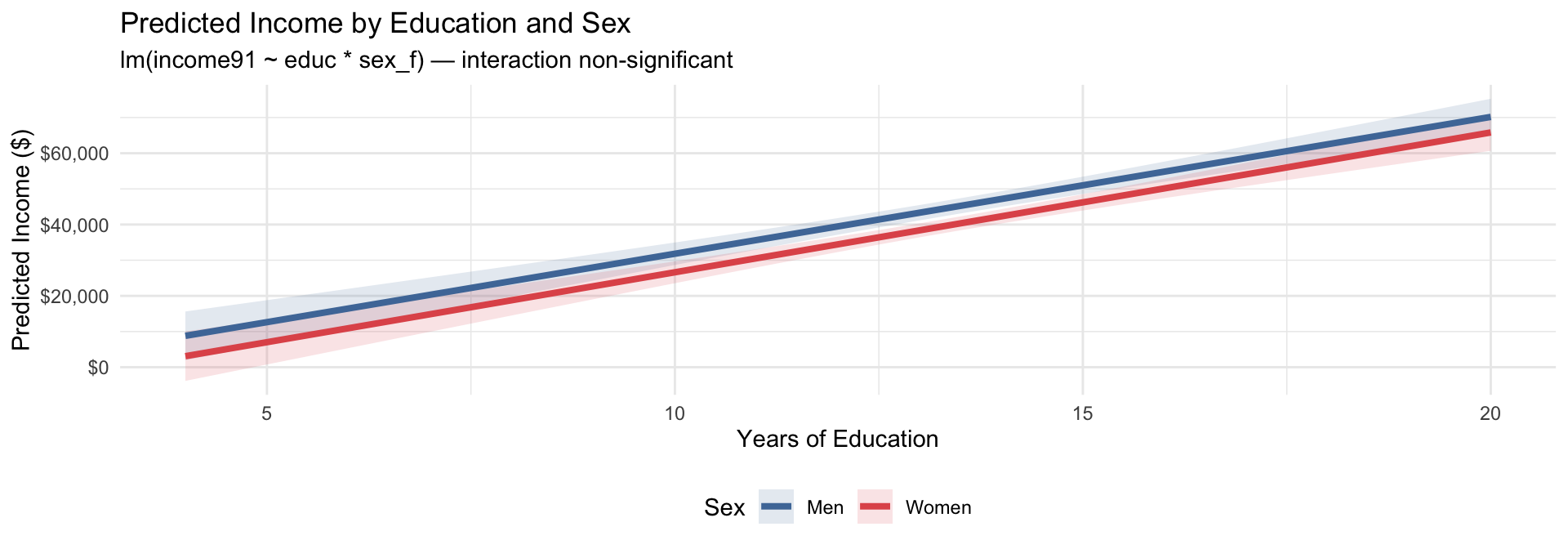
Model: lm(income ~ Black * female) — does the racial income gap differ by sex?
Code
ggpredict(model_bb, terms = c("Black", "female")) |>
ggplot(aes(x = x, y = predicted, color = group, group = group)) +
geom_point(size = 4) +
geom_line(linewidth = 1.2) +
geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width = 0.08, linewidth = 1.0) +
scale_color_manual(
values = c("Men" = "#4E79A7", "Women" = "#E15759"), name = "Sex"
) +
scale_y_continuous(labels = scales::dollar_format(big.mark = ",")) +
labs(
title = "Predicted Income by Race and Sex",
subtitle = "lm(income ~ Black * female) — interaction: non-additivity of race and sex gaps",
x = "Race",
y = "Predicted Income ($)"
) +
theme_minimal(base_size = 11) +
theme(legend.position = "bottom")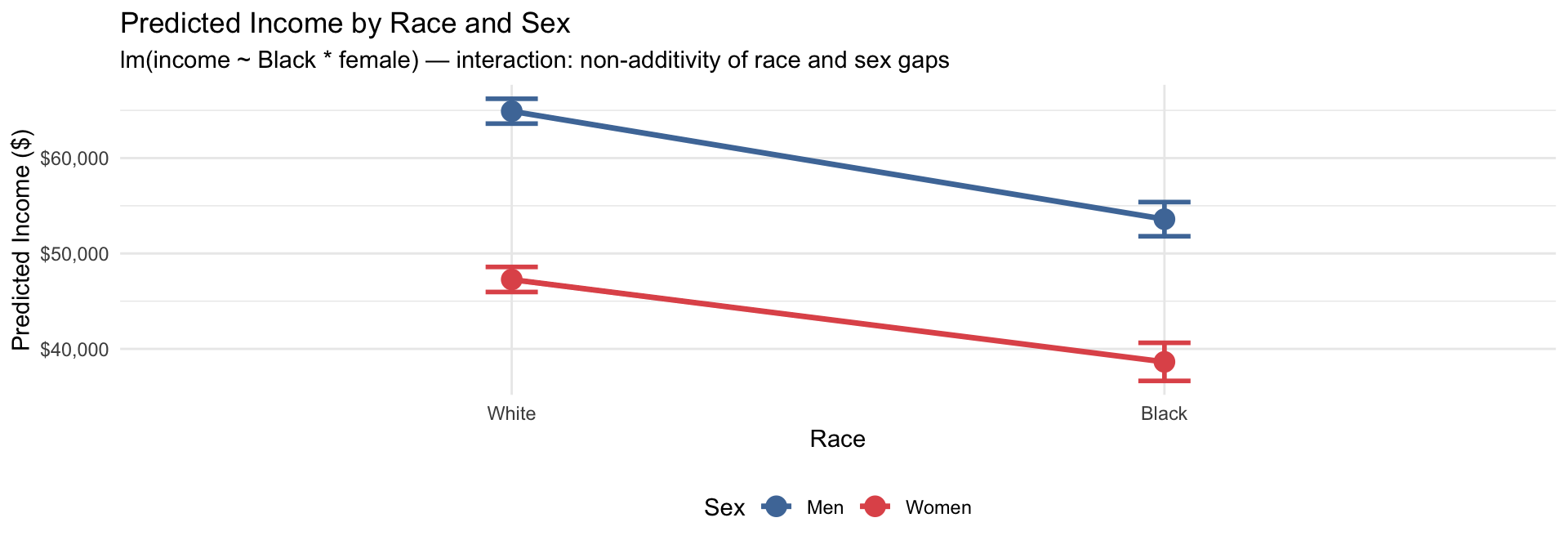
Interaction Model Results
Code
modelsummary(
list("No Interaction" = model_main,
"With Interaction" = model_interact),
coef_rename = c("(Intercept)" = "Intercept",
"educ" = "Years of Education",
"sex_ffemale" = "Female",
"educ:sex_ffemale" = "Education × Female"),
stars = TRUE,
fmt = 0,
title = "OLS: Income ~ Education × Sex",
gof_map = c("nobs", "r.squared", "adj.r.squared")
)| No Interaction | With Interaction | |
|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | ||
| Intercept | -7092* | -6547 |
| (3557) | (4848) | |
| Years of Education | 3877*** | 3836*** |
| (254) | (354) | |
| Female | -4919*** | -6038 |
| (1472) | (6928) | |
| Education × Female | 84 | |
| (508) | ||
| Num.Obs. | 2517 | 2517 |
| R2 | 0.089 | 0.089 |
| R2 Adj. | 0.088 | 0.088 |
We can also calculate predicted incomes for specific profiles:
# A tibble: 4 × 3
educ sex_f predicted_income
<dbl> <chr> <chr>
1 12 male $39,489
2 12 female $34,458
3 16 male $54,834
4 16 female $50,139 Code
ggpredict(model_interact, terms = c("educ [4:20 by=0.5]", "sex_f")) |>
ggplot(aes(x = x, y = predicted, color = group, fill = group)) +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = 0.15, color = NA) +
geom_line(linewidth = 1.4) +
scale_color_manual(values = c("male" = "#4E79A7", "female" = "#E15759"),
labels = c("Men", "Women"), name = "Sex") +
scale_fill_manual(values = c("male" = "#4E79A7", "female" = "#E15759"),
labels = c("Men", "Women"), name = "Sex") +
scale_y_continuous(labels = scales::dollar_format(big.mark = ",")) +
labs(
title = "With interaction: diverging slopes (non-significant)",
subtitle = "lm(income91 ~ educ * sex_f)",
x = "Years of Education", y = "Predicted Income ($)"
) +
theme_minimal(base_size = 11) +
theme(legend.position = "bottom")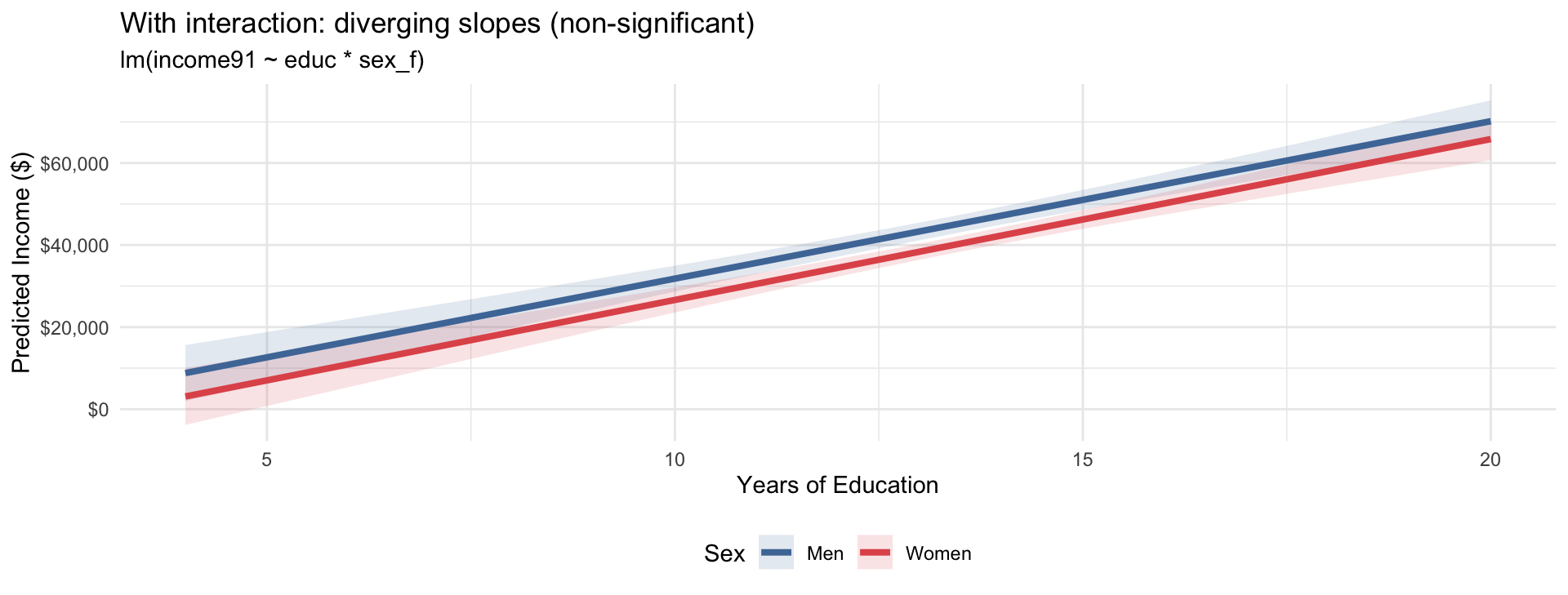
Interactions in Logistic Regression
Interaction terms work the same way in logistic regression — same syntax, same logic. Let’s look at the interaction of education and sex on likely union membership.
Code
attain_logit <- attain |>
filter(!is.na(union_member), !is.na(educ), !is.na(sex_f))
# Logistic regression with interaction
model_logit_int <- glm(union_member ~ educ * sex_f,
family = binomial,
data = attain_logit)
modelsummary(model_logit_int,
exponentiate = TRUE,
coef_rename = c("(Intercept)" = "Intercept",
"educ" = "Years of Education",
"sex_ffemale" = "Female",
"educ:sex_ffemale" = "Education × Female"),
stars = TRUE,
title = "Logistic Regression with Interaction (Odds Ratios)",
gof_map = c("nobs", "AIC"))| (1) | |
|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |
| Intercept | 0.337** |
| (0.120) | |
| Years of Education | 0.931** |
| (0.025) | |
| Female | 0.018*** |
| (0.012) | |
| Education × Female | 1.278*** |
| (0.058) | |
| Num.Obs. | 2985 |
Code
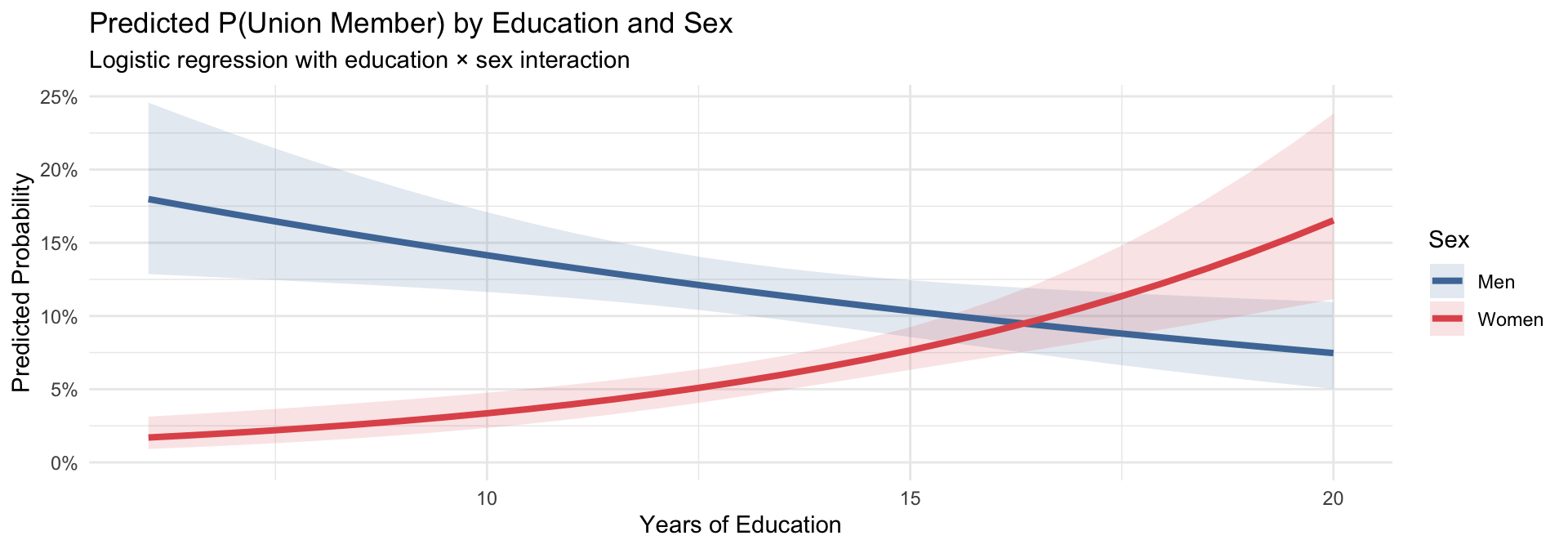
ggpredict(model_logit_int, terms = c("educ [6:20 by=0.5]", "sex_f")) |>
(\(pred) {
ggplot(pred, aes(x = x, y = predicted, color = group, fill = group)) +
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = 0.15, color = NA) +
geom_line(linewidth = 1.4) +
scale_color_manual(values = c("male" = "#4E79A7", "female" = "#E15759"),
labels = c("Men", "Women"), name = "Sex") +
scale_fill_manual(values = c("male" = "#4E79A7", "female" = "#E15759"),
labels = c("Men", "Women"), name = "Sex") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1),
limits = c(0, NA)) +
labs(
title = "Predicted P(Union Member) by Education and Sex",
subtitle = "Logistic regression with education × sex interaction",
x = "Years of Education",
y = "Predicted Probability"
) +
theme_minimal(base_size = 11)
})()