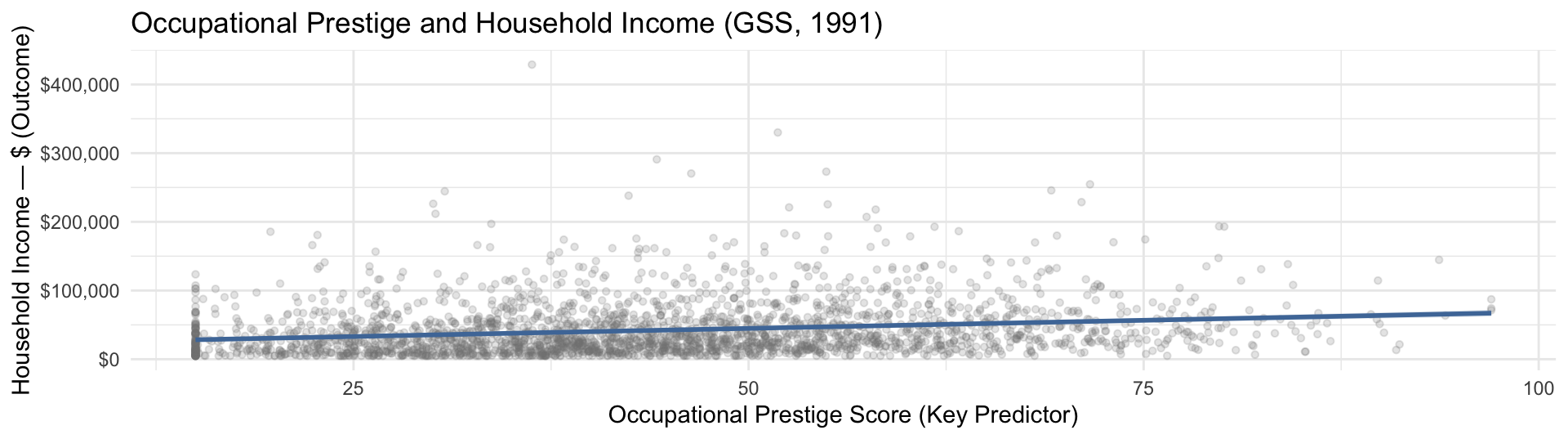
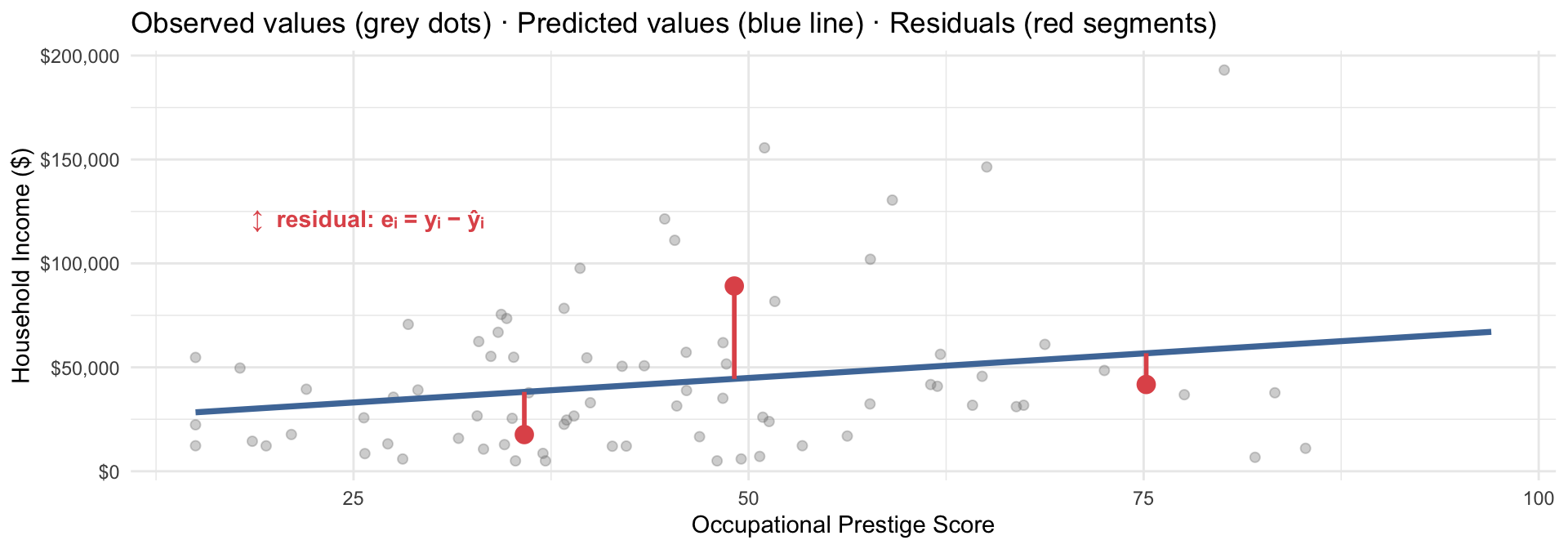
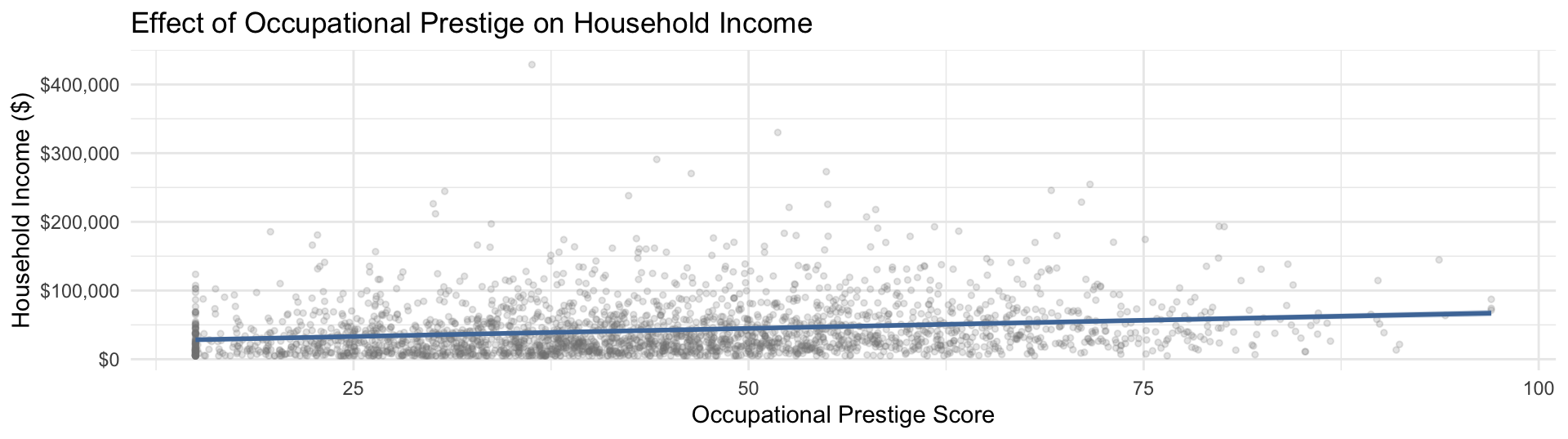
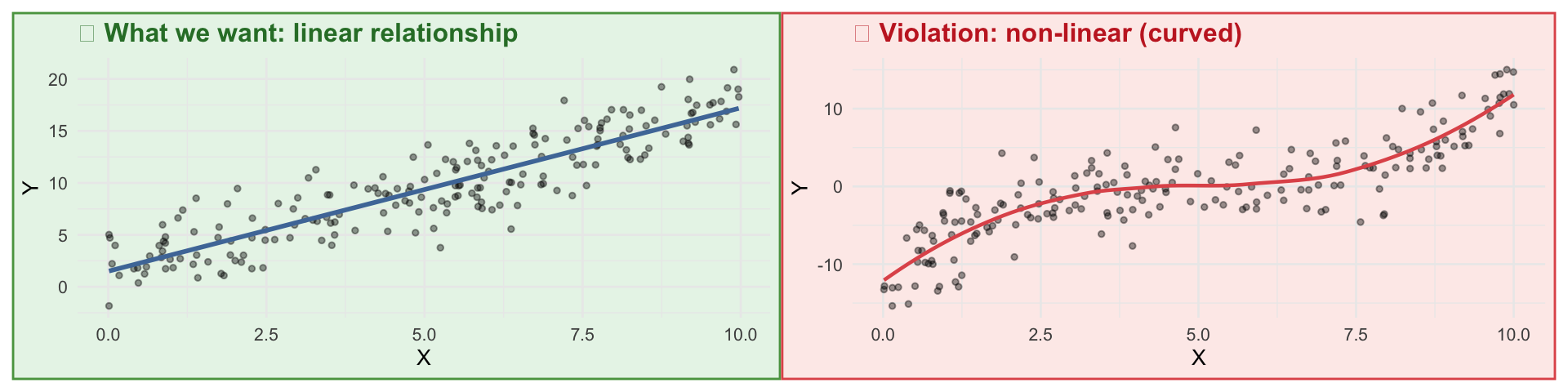
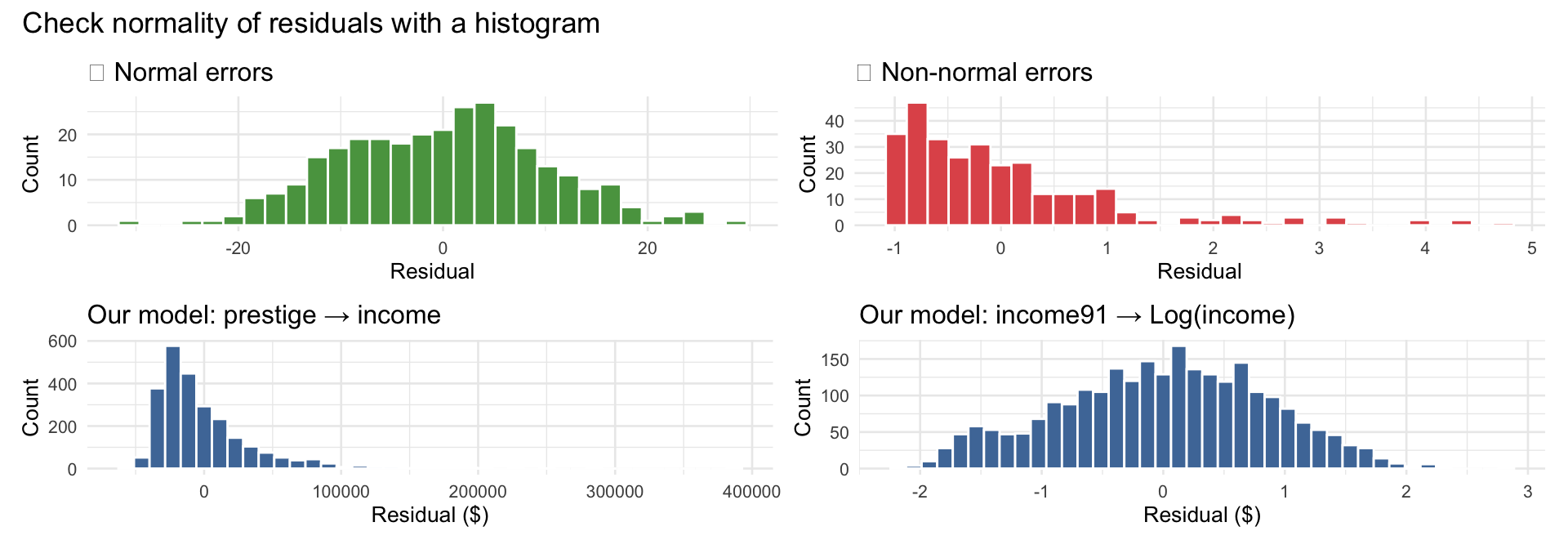
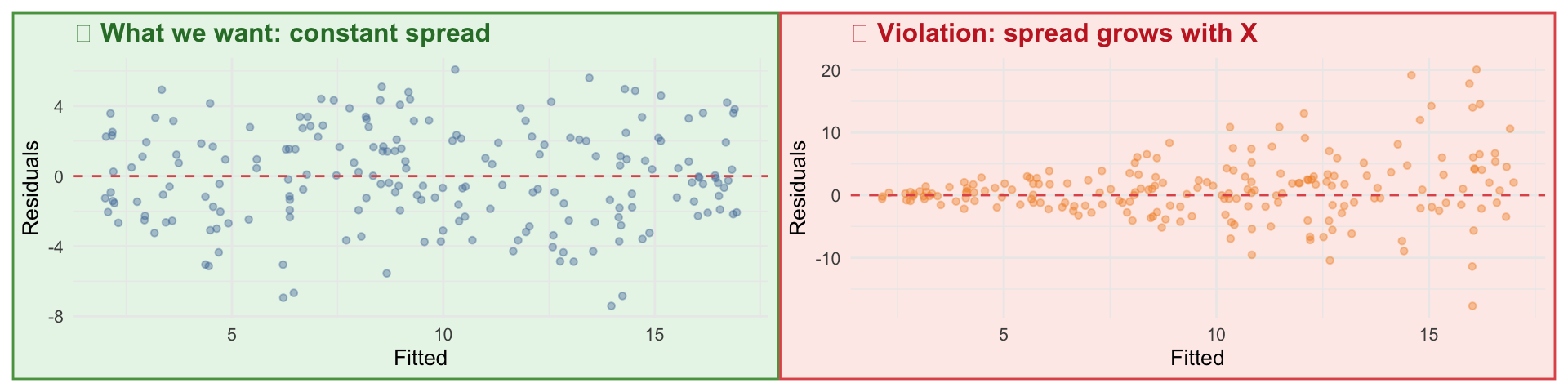
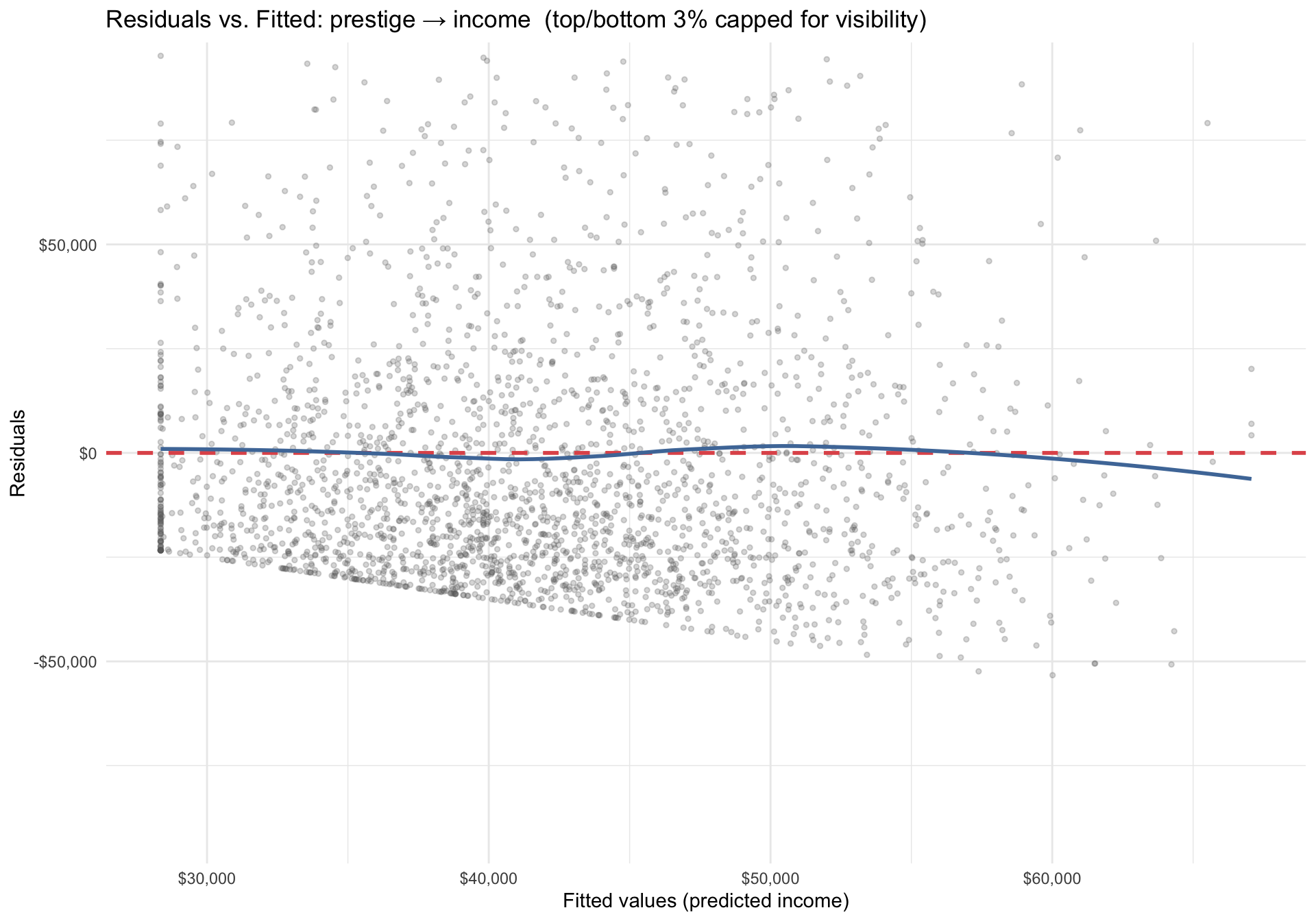
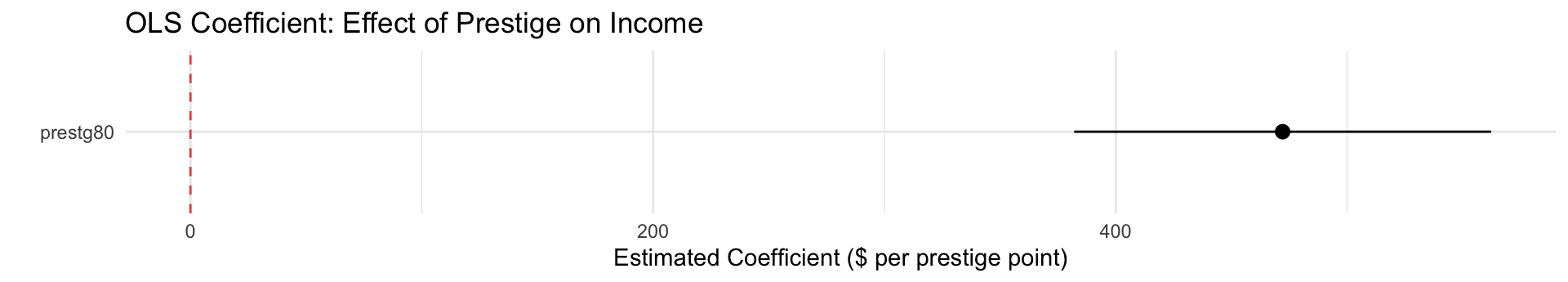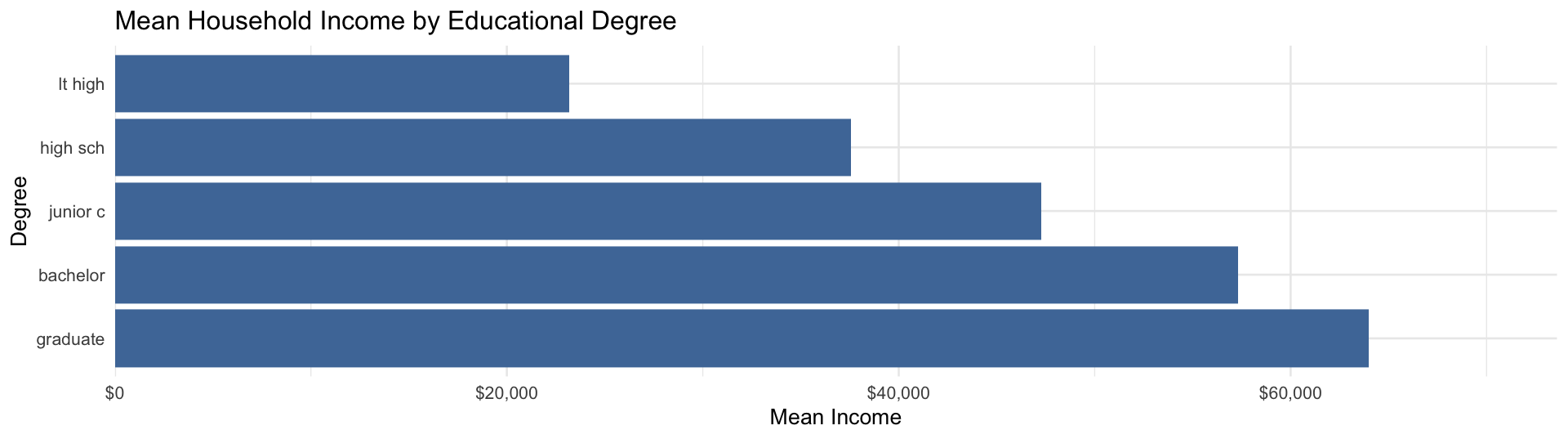Intercept: Predicted income when prestige = 0. Not substantively meaningful for prestige (no one has a prestige score of 0) — just the mathematical anchor for the line.
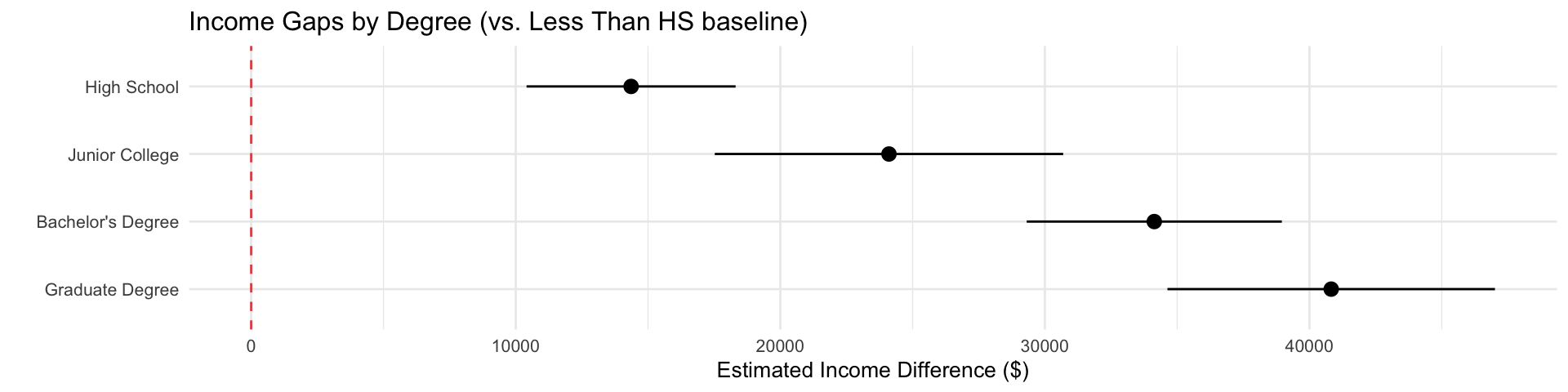
Prestige Score (slope): For each additional point in occupational prestige, household income is predicted to be about $472 higher, on average. This is your key result.
Standard error: How precisely we’ve estimated the slope. Smaller SE → more confidence.
Stars / p-value: Is the slope significantly different from zero? Here, \(p < 0.001\) — we strongly reject \(H_0: \beta = 0\).
R²: Occupational prestige explains about 4% of the variation in household income. Report and interpret this in hw9.